2014年6月19日星期四
2014年6月10日星期二
使用 CStdioFile 按行读入文件数据
CStdioFile 是 MFC 封装的 std::ifstream 和 std::ofstream 形成的一个类,可以按行从文件读入数据,使用起来非常的方便,详细使用说明参考 http://msdn.microsoft.com/en-us/library/a499td6y.aspx。
一个简单的读自定义点云文件(坐标、颜色及法向)的函数范例如下:
void ReadCloudFile(const CString & path, pcl::PointCloud<pcl::PointXYZRGB> & cloud, pcl::PointCloud<pcl::Normal> & normal)
{
cloud.clear();
normal.clear();
CStdioFile file;
if (!file.Open(path, CFile::modeRead))
{
return;
}
CString line;
while (file.ReadString(line))
{
if (line.IsEmpty())
{
continue;
}
double X,Y,Z,nX,nY,nZ;
int R,G,B;
sscanf(line, "%lf;%lf;%lf;%d;%d;%d;%lf;%lf;%lf", &X, &Y, &Z, &R, &G, &B, &nX, &nY, &nZ);
pcl::PointXYZRGB p;
pcl::Normal n;
p.x = X;
p.y = Y;
p.z = Z;
p.r = R;
p.g = G;
p.b = B;
n.normal_x = nX;
n.normal_y = nY;
n.normal_z = nZ;
cloud.push_back(p);
normal.push_back(n);
}
file.Close();
}
一个简单的读自定义点云文件(坐标、颜色及法向)的函数范例如下:
void ReadCloudFile(const CString & path, pcl::PointCloud<pcl::PointXYZRGB> & cloud, pcl::PointCloud<pcl::Normal> & normal)
{
cloud.clear();
normal.clear();
CStdioFile file;
if (!file.Open(path, CFile::modeRead))
{
return;
}
CString line;
while (file.ReadString(line))
{
if (line.IsEmpty())
{
continue;
}
double X,Y,Z,nX,nY,nZ;
int R,G,B;
sscanf(line, "%lf;%lf;%lf;%d;%d;%d;%lf;%lf;%lf", &X, &Y, &Z, &R, &G, &B, &nX, &nY, &nZ);
pcl::PointXYZRGB p;
pcl::Normal n;
p.x = X;
p.y = Y;
p.z = Z;
p.r = R;
p.g = G;
p.b = B;
n.normal_x = nX;
n.normal_y = nY;
n.normal_z = nZ;
cloud.push_back(p);
normal.push_back(n);
}
file.Close();
}
Conflict between window macro min max and std::min std::max
在新建一个新的 MFC 工程并单独添加 PCL 的时候,编译过程出现错误,提示 PCL 的相关文件中的 min 函数的输入参数个数不对,这其实是因为 windows 自己在 <window.h> 头中定义了宏 min 和 max 函数,而 PCL 中使用的 min 和 max 是 stl 中的函数,于是就产生了冲突,在网上找到一篇 microsoft 官方微博提供的关于此问题的一个解决方案:
http://support.microsoft.com/kb/143208
他的做法是在 Project->Properties->Configuration Properties->C/C++->Preprocessor->Preprocessor Definitions 中添加一个 NOMINMAX 的宏定义,这样的话 windows 自己的宏 min max 函数就不会被定义了,但是这样的做法是导致 MFC 中自己包含的很多确实用到该宏 min max 函数的地方报错,提示 min max 函数没定义,到此该问题的解决貌似成了一个鱼和熊掌不可兼得的情况。
回到 PCL 用户论坛继续找解决方案,最终找到一个方案,那就是在 stdafx.h 添加完所有 windows 自己头文件后,添加任何 PCL 头文件之前,通过 #undef 宏命令取消 windows 自己宏 min max 函数的定义:
#include "targetver.h"
#define _ATL_CSTRING_EXPLICIT_CONSTRUCTORS // some CString constructors will be explicit
// turns off MFC's hiding of some common and often safely ignored warning messages
#define _AFX_ALL_WARNINGS
#include <afxwin.h> // MFC core and standard components
#include <afxext.h> // MFC extensions
#include <afxdisp.h> // MFC Automation classes
#ifndef _AFX_NO_OLE_SUPPORT
#include <afxdtctl.h> // MFC support for Internet Explorer 4 Common Controls
#endif
#ifndef _AFX_NO_AFXCMN_SUPPORT
#include <afxcmn.h> // MFC support for Windows Common Controls
#endif // _AFX_NO_AFXCMN_SUPPORT
#include <afxcontrolbars.h> // MFC support for ribbons and control bars
#undef max
#undef min
#include <pcl/point_types.h>
#include <pcl/io/io.h>
这样的话所有的 windows 头还是用自己定义的 min max 函数,而所有 pcl 的库就用的 stl 的 min max 函数,这样做是合理的,因为 pcl 中肯定不会用到 windows 定义的 min max 函数。
http://support.microsoft.com/kb/143208
他的做法是在 Project->Properties->Configuration Properties->C/C++->Preprocessor->Preprocessor Definitions 中添加一个 NOMINMAX 的宏定义,这样的话 windows 自己的宏 min max 函数就不会被定义了,但是这样的做法是导致 MFC 中自己包含的很多确实用到该宏 min max 函数的地方报错,提示 min max 函数没定义,到此该问题的解决貌似成了一个鱼和熊掌不可兼得的情况。
回到 PCL 用户论坛继续找解决方案,最终找到一个方案,那就是在 stdafx.h 添加完所有 windows 自己头文件后,添加任何 PCL 头文件之前,通过 #undef 宏命令取消 windows 自己宏 min max 函数的定义:
#include "targetver.h"
#define _ATL_CSTRING_EXPLICIT_CONSTRUCTORS // some CString constructors will be explicit
// turns off MFC's hiding of some common and often safely ignored warning messages
#define _AFX_ALL_WARNINGS
#include <afxwin.h> // MFC core and standard components
#include <afxext.h> // MFC extensions
#include <afxdisp.h> // MFC Automation classes
#ifndef _AFX_NO_OLE_SUPPORT
#include <afxdtctl.h> // MFC support for Internet Explorer 4 Common Controls
#endif
#ifndef _AFX_NO_AFXCMN_SUPPORT
#include <afxcmn.h> // MFC support for Windows Common Controls
#endif // _AFX_NO_AFXCMN_SUPPORT
#include <afxcontrolbars.h> // MFC support for ribbons and control bars
#undef max
#undef min
#include <pcl/point_types.h>
#include <pcl/io/io.h>
这样的话所有的 windows 头还是用自己定义的 min max 函数,而所有 pcl 的库就用的 stl 的 min max 函数,这样做是合理的,因为 pcl 中肯定不会用到 windows 定义的 min max 函数。
2014年6月9日星期一
PCLVisualizer visualize my own point cloud and normals
经过一上午的代码整合与调试,终于可以通过 PCLVisualizer 来显示自己的点云和法向场了,效果如下:



需要注意的一点是在退出该三维显示窗口时最好是直接点叉关闭掉,如果是通过按 q 键来退出窗口的话,貌似显示内循环不会结束,就会导致内存泄露。
需要注意的一点是在退出该三维显示窗口时最好是直接点叉关闭掉,如果是通过按 q 键来退出窗口的话,貌似显示内循环不会结束,就会导致内存泄露。
error C2661: 'pcl::PointCloud::operator new' : no overloaded function takes 3 arguments
在 MFC 程序中使用如下语句时
pcl::PointCloud<pcl::PointXYZRGB>::Ptr cloud(new pcl::PointCloud<pcl::PointXYZRGB>);
pcl::PointCloud<pcl::Normal>::Ptr normal(new pcl::PointCloud<pcl::Normal>);
编译的时候会出现如下错误
error C2661: 'pcl::PointCloud<PointT>::operator new' : no overloaded function takes 3 arguments
google 一番发现这是因为 MFC wizard 为了跟踪内存分配在每个 MFC .cpp 中都加了以下三句话
#ifdef _DEBUG
#define new DEBUG_NEW
#endif
重新定义了 new,因此把每个 MFC .cpp 中的这三句屏蔽掉就可以编译通过了。
pcl::PointCloud<pcl::PointXYZRGB>::Ptr cloud(new pcl::PointCloud<pcl::PointXYZRGB>);
pcl::PointCloud<pcl::Normal>::Ptr normal(new pcl::PointCloud<pcl::Normal>);
编译的时候会出现如下错误
error C2661: 'pcl::PointCloud<PointT>::operator new' : no overloaded function takes 3 arguments
google 一番发现这是因为 MFC wizard 为了跟踪内存分配在每个 MFC .cpp 中都加了以下三句话
#ifdef _DEBUG
#define new DEBUG_NEW
#endif
重新定义了 new,因此把每个 MFC .cpp 中的这三句屏蔽掉就可以编译通过了。
error C3859: virtual memory range for PCH exceeded; please recompile with a command line option of '-Zm283' or greater
PCL confict with OpenCV : ‘flann’ : ambiguous symbol
昨天将 PCL 整合到大工程当中时,PCL 和 OpenCV 发生了冲突,PCL 中的第三方库 flann 和OpenCV 中的 cv::flann 产生了模糊,在 PCL 用户论坛还有 google 上找了一圈发现一个解决方案,就是将所有 PCL flann 库中的 flann:: 都改成 ::flann:: 编译就可以通过了,还不知道这是不是最优的解决方案。
另外我还是把 PCL 从 C 盘挪到了 D 盘,因为为了解决上面的问题需要修改 PCL 目录下的代码,在 C 盘由于权限无法完成修改,于是还是整体挪到了 D 盘,并相应的把环境变量路径改了过来。
2014年6月8日星期日
Installation of Point Cloud Library (PCL) and integration with Visual studio 2010 project
自从知道 Point Cloud Library (PCL) 之后就一直想用上它,尤其是其中的 point cloud visualization 模块以及 surface reconstruction 模块,可以更直观的呈现算法的结果。
首先到 http://pointclouds.org/downloads/windows.html 上面下载 PCL 1.6.0 All-In-One Installer,里面包含了 PCL 以及所有第三方库的头文件以及库文件等,下下来之后点击安装,在安装完成后选择为所有用户添加 PCL 路径。
完成安装后会发现此时系统已经自动将 PCL 的安装根目录 C:\Program Files\PCL 1.6.0 设为系统环境变量 PCL_ROOT,另外在默认索引 .dll 文件的 Path 系统变量中也已经添加了 C:\Program Files\PCL 1.6.0\bin 路径,避免了手动拷贝 .dll 到工程目录的必要。
接着在 VS2010 中新建了一个 win32 console 工程专门用来测试 PCL tutorials,并添加如下路径:
于 Project->Properties->Configuration Properties->C/C++->General->Additional Include Directories 中添加
$(PCL_ROOT)\include\pcl-1.6
$(PCL_ROOT)\3rdParty\Boost\include
$(PCL_ROOT)\3rdParty\Eigen\include
$(PCL_ROOT)\3rdParty\FLANN\include
$(PCL_ROOT)\3rdParty\Qhull\include
$(PCL_ROOT)\3rdParty\VTK\include\vtk-5.8
于 Project->Properties->Configuration Properties->Linker->General->Additional Library Directories 中添加
$(PCL_ROOT)\lib
$(PCL_ROOT)\3rdParty\Boost\lib
$(PCL_ROOT)\3rdParty\FLANN\lib
$(PCL_ROOT)\3rdParty\Qhull\lib
$(PCL_ROOT)\3rdParty\VTK\lib\vtk-5.8
最后要做的是把需要的 .lib 文件添加到
Project->Properties->Configuration Properties->Linker->Input->Additional Dependencies 中。
这里我没管哪些函数具体是包含在哪个 .lib 文件中,而是一股脑的把所有 debug 的 .lib 全部添加到了里面,省事,另外要强调的是 PCL 中所有可视函数不管是简单的 pcl::visualization::CloudViewer 还是功能强大的 pcl::visualization::PCLVisualizer 都是基于 VTK 显示库,所以要使用显示模块,VTK 的所有相关的 .lib 文件都得添加进来,最最需要注意的是 VTK 库函数中有很多是封装了 OpenGL 的基本函数,因此还得将 opengl32.lib 给添加进来,否则很多 VTK 函数会出现链接错误。
接着就准备开始测试,本来 PCL 安装好之后在其安装目录 $(PCL_ROOT)\share\doc\pcl-1.6\tutorials\sources 中有一个总的 CMakeLists 可以通过 CMake 2.8 make 出一个总的 PCLTutorial 工程来,其中包含了所有的 tutorials 工程,这里要注意的是,makefile 的时候输出路径尽量别选在 C:\ 中有权限限制的区域,可能无法 makefile,我最终是选择的输出在桌面。如此生成的工程虽然包含了所有的 tutorials 但是编译不能成功,提示需要 Qt 相关的 .lib 文件,即使单独运行某一个 tutorial 也不行,所以最终我还是选择了将单个感兴趣的 tutorial 代码粘贴到上面自己新建的 win32 console 工程来进行测试的方式。
其中 pcl_visualizer tutorial 运行的效果如下所示:


cloud_viewer tutorial 运行的效果如下所示:

总共有 46 万个点,在 debug 模式下显示的还是挺流畅的,感觉很不错,唯一不足的是响应鼠标拖动旋转的方式还是没有 CloudCompare 用着舒服。
最后要注意的是 pcl_visualizer tutorial 中的 int main(int argc, char ** argv) 函数需要根据用户输入的 argv 参数中的内容来进行不同模式的显示,这个参数是在调用 main 函数时输入的,做法就是通过命令提示符进入到 .exe 所在目录,然后通过如下格式输入不同参数来调用 main 函数:

首先到 http://pointclouds.org/downloads/windows.html 上面下载 PCL 1.6.0 All-In-One Installer,里面包含了 PCL 以及所有第三方库的头文件以及库文件等,下下来之后点击安装,在安装完成后选择为所有用户添加 PCL 路径。
完成安装后会发现此时系统已经自动将 PCL 的安装根目录 C:\Program Files\PCL 1.6.0 设为系统环境变量 PCL_ROOT,另外在默认索引 .dll 文件的 Path 系统变量中也已经添加了 C:\Program Files\PCL 1.6.0\bin 路径,避免了手动拷贝 .dll 到工程目录的必要。
接着在 VS2010 中新建了一个 win32 console 工程专门用来测试 PCL tutorials,并添加如下路径:
于 Project->Properties->Configuration Properties->C/C++->General->Additional Include Directories 中添加
$(PCL_ROOT)\include\pcl-1.6
$(PCL_ROOT)\3rdParty\Boost\include
$(PCL_ROOT)\3rdParty\Eigen\include
$(PCL_ROOT)\3rdParty\FLANN\include
$(PCL_ROOT)\3rdParty\Qhull\include
$(PCL_ROOT)\3rdParty\VTK\include\vtk-5.8
于 Project->Properties->Configuration Properties->Linker->General->Additional Library Directories 中添加
$(PCL_ROOT)\lib
$(PCL_ROOT)\3rdParty\Boost\lib
$(PCL_ROOT)\3rdParty\FLANN\lib
$(PCL_ROOT)\3rdParty\Qhull\lib
$(PCL_ROOT)\3rdParty\VTK\lib\vtk-5.8
最后要做的是把需要的 .lib 文件添加到
Project->Properties->Configuration Properties->Linker->Input->Additional Dependencies 中。
这里我没管哪些函数具体是包含在哪个 .lib 文件中,而是一股脑的把所有 debug 的 .lib 全部添加到了里面,省事,另外要强调的是 PCL 中所有可视函数不管是简单的 pcl::visualization::CloudViewer 还是功能强大的 pcl::visualization::PCLVisualizer 都是基于 VTK 显示库,所以要使用显示模块,VTK 的所有相关的 .lib 文件都得添加进来,最最需要注意的是 VTK 库函数中有很多是封装了 OpenGL 的基本函数,因此还得将 opengl32.lib 给添加进来,否则很多 VTK 函数会出现链接错误。
接着就准备开始测试,本来 PCL 安装好之后在其安装目录 $(PCL_ROOT)\share\doc\pcl-1.6\tutorials\sources 中有一个总的 CMakeLists 可以通过 CMake 2.8 make 出一个总的 PCLTutorial 工程来,其中包含了所有的 tutorials 工程,这里要注意的是,makefile 的时候输出路径尽量别选在 C:\ 中有权限限制的区域,可能无法 makefile,我最终是选择的输出在桌面。如此生成的工程虽然包含了所有的 tutorials 但是编译不能成功,提示需要 Qt 相关的 .lib 文件,即使单独运行某一个 tutorial 也不行,所以最终我还是选择了将单个感兴趣的 tutorial 代码粘贴到上面自己新建的 win32 console 工程来进行测试的方式。
其中 pcl_visualizer tutorial 运行的效果如下所示:
cloud_viewer tutorial 运行的效果如下所示:
总共有 46 万个点,在 debug 模式下显示的还是挺流畅的,感觉很不错,唯一不足的是响应鼠标拖动旋转的方式还是没有 CloudCompare 用着舒服。
最后要注意的是 pcl_visualizer tutorial 中的 int main(int argc, char ** argv) 函数需要根据用户输入的 argv 参数中的内容来进行不同模式的显示,这个参数是在调用 main 函数时输入的,做法就是通过命令提示符进入到 .exe 所在目录,然后通过如下格式输入不同参数来调用 main 函数:
留学期间阅读的文献汇总,三季度
1. Fast Range Image Segmentation and Smoothing Using Approximate Surface Reconstruction and Region Growing (completely read on 7th Jun 2014).
这是德国 University of Bonn 的 Dirk Holz 和 Sven Behnke 在 2013 年第 12 届 intelligent autonomous systems 大会上发表的一篇文章。
我其实是在 Point Cloud Library (PCL) 的 Surface extraction 模块的文档介绍中看到该文章的,因为 PCL 的 surface 模块里有一个函数 pcl::OrganizedFastMesh< PointInT > 就是实现的该文的算法。
正如本文题目中申明的那样,其最主要的目的是对深度图进行分割和平滑,我看本文主要的目的是看他里面如何对 organized point cloud (e.g. range image) 进行快速 mesh。文章的第 2 大节中把 range image segmentation 方法分为 3 大类:RANSAC, 3D Hough transform and region growing,作为了解。
直奔我最关心的 fast approximate meshing,其实我认为文中关于这部分的描述有问题,每次少考虑了邻域中的一个像素,关于我自己对 fast approximate meshing 的理解在笔记本里有详细叙述。然后关于其算法中如何快速求 mesh 中每个 vertex 的法向,以及后续如何对每个 vertex 的位置及其法向利用其与邻域 vertices 之间位置、法向以及颜色的邻近程度来进行 bilateral filtering 也一概在笔记本中有详细描述。
2. Occluding Contours for Multi-View Stereo (completely read on 8th Jun 2014).
本文是 Qi Shan, B. Curless, Y. Furukawa 以及 S. M. Seitz 在 2014 年的一篇文章。
3. Accurate Multiple View 3D Reconstruction Using Patch-Based Stereo for Large-Scale Scenes (completely read on 16th Jun 2014).
这篇文章是 SWJTU 的一位校友 Shuhan Shen 于 2013 年发表在 IEEE TRANSACTIONS ON IMAGE PROCESSING 上一篇文章,该校友 06 年于 SWJTU 毕业,之后于 10 年又拿到了 SJTU 的博士学位,现就职于北京中科院模式识别自动化所。
这篇文章的思路对于我来说还是很清晰的,该算法也是输入一堆图像,然后输出是为每个输入图像生成了一幅深度图,他的算法主要分成以下 4 步骤:
一、Stereo Pair Selection. 首先为每一幅图像选择一幅支持图像,文中将支持图像称为 reference image,whatever,选择的准则就是两幅图之间要有相似的视线角,以及不能太宽(重合区域少)也不能太窄(重建精度低)的基线,具体方法参考原文,总之其同时考虑了视线夹角以及基线长度;
二、Depth-Map Computation. 这一部分是该文最核心的部分,与当前我的方法中采用深度梯度来表示表面法向的方式不同,该文中采用的是真正的空间平面解析表达式的形式,当时我认为要解析的表示出该空间平面需要多于两个自由度的参数,但是却从未想过可以把平面放到像机坐标系下用两个球体极坐标来表示,这样平面法向参数表示也就是两个自由度了。有了空间平面的解析表示后,就可以通过空间平面诱导出两图像间的单应了,匹配像点之间的转移也更为简单(左乘诱导单应)。其后的过程我已经很熟悉了;
三、Depth-Map Refinement. 这一部分其实就是利用我的方法中 depth consistency check 来剔除 outliers;
四、Depth-Map Merging. 这一步中作者要做的是把匹配的很多冗余量给剔除掉,但实际上这样做损失了精度,没有将冗余观测利用起来提高重建精度。
4. Quasi-Dense 3D Reconstruction using Tensor-Based Multiview Stereo (completely read on 18th Jun 2014).
这篇文章是香港科技大学 (HKUST) Tai-Pang Wu 2010 年的一篇 CVPR 文章,文献【3】的 Introduction 中有介绍该文章,所以就下下来看了。
该文方法基于 PMVS 的主体框架,在其各个环节中引入 Tensor Voting 机制以优化得到更准的法向估计和坐标,以及更好的剔除 outliers。
关于 Tensor voting 可以参考 T. P. Wu 2012 年的 TPAMI 文章。
该文方法主要将 Tensor voting 用到了 PMVS 的一下 3 个环节:
一、Match. 也就是 PMVS 中对 features 进行稀疏重建的环节,这个环节中 tensor voting 的介入有两种情况,一种是当图像未标定的时候,也就是内定向及外定向未知时,这时候一般的做法是进行 SfM 通过 RANSAC 来先估计两视图间的基础矩阵同时进行特征匹配,而本文提出一种基于 Expectation-Maximization 参数估计方法的 EMTV 算法可以用来同时估计基础矩阵和进行匹配,是类似于 RANSAC 的一种鲁棒方法,据文中给出的结果 EMTV 方法得到了更好的稀疏重建结果;另一种情形就是当图像完成了标定的时候,这时候 TV 可以用来优化稀疏重建的 patches 的法向,做法就是每个 patch 都收集其邻近的 patches 的张量,得到其更新的张量,并从中得到新法向,以下是经过 TV 前后的法向重建结果对比;

二、Propagation. PMVS 原文中的做法是根据已经存在的 patches 的法向和邻域先生成一系列候选的三维点位,然后沿每个候选点的视线方向去优化该候选点的法向和位置。本文方法也将 TV 应用在了这一环节中,具体点就是应用在了候选点法向和位置的优化上,它是怎么去优化的呢,首先也是沿着候选点的视线方向去调整采样,并记录每个采样位置处的 photoconsistency (NCC) 程度和 surface saliency 程度(邻域内对该采样位置处的 TV),并定义了如下的一个同时考虑了photoconsistency 和 surface saliency 的综合指标,并最终选择拥有最优该指标的采样位置和得到的法向作为最终优化值;

三、Filtering. 这一步里面作者用其所谓的 MRF-TV 来进一步剔除 outliers,详见原文。
5. A Closed-Form Solution to Tensor Voting: Theory and Applications (completely read on 19th Jun 2014).
上文作者 Tai-Pang Wu 于 2010 年发表在 TPAMI 上的一篇详细介绍其 CFTV 原理的文章,里面有一些思路很巧妙的地方,尤其是给定一个位置上的法向,如何推断指定点位上的最有可能的法向,其实 Tensor voting 的思想最早是由 University of South California 的 Gerard G. Medioni 教授提出来的,只不过在 CFTV 之前的 TV 应用都是先要计算一些 precomputed tensor fields,也就是说是数值的形式,而这里 CFTV 是闭合的解析的形式,计算点 j 处张量 Kj 在点 i 处的投票直接使用如下式子,而无需再事先计算 precomputed voting fields 了,其实关于其中的积分公式我有详细的笔记和解读。

6. Combined Depth and Outlier Estimation in Multi-View Stereo (completely read on 24th Jun 2014).
C. Strecha 2006 年的一篇 CVPR,很早之前就尝试着看过一两次,但都没有看太明白,主要是对其中采用的 Expectation-Maximizaiton 思想不太明白,但是最近自学了参数估计里的 MLE, MAP, Bayesian Estimator 和 EM 算法之后,现在终于算是明白这篇文章的方法了,该文中的方法思路还是非常有创造性的,详细的理解和解读在笔记当中有。
7. PM-Huber: PatchMatch with Huber Regularization for Stereo Matching (completely read on 29th Jun 2014).
这是慕尼黑工业大学的 P. Heise 在 2013 年发表的一篇 ICCV 文章,文章的方法还是 Binocular stereo 方法,需要对两视图进行图像矫正,考虑的还是视差,另外其采用的 support window model 依然是 M. Bleyer 2011 年文章中的模型,即 disparity space plane model,只不过本文中对 window 中像素在两视图中的转移公式用单应解析的表示出来了。
可以这么说吧,本文并不是我一开始设想的是在原 PatchMatch 的框架中加入了 smoothness 项,然后最终结果可以达到能量函数全局最优的这么一种方式,本文的方法实际上应该是早就有了一个分步交替求解全局最优的框架,只不过其中的一步原本涉及到 brutal force searching 本文就想到了用 PatchMatch 来代替原来的 brutal force searching 提高计算速度。
本文最核心的思路就是借鉴了 Frank Steinbrucker 2009 年在 ICCV 的文章 Large Displacement Optical Flow Computation without Warping 中的思路,就是把传统的能量函数通过使用 Quadratic relaxation,即添加一个 auxiliary parameter field 构成一个 quadratic term 将之前的耦合在一起的 data term 和 smoothness term 解耦成两个独立的优化问题,如下式所示。

其中 u 和 v 是两个参数场,每个像素都包含了视差和法向参数,已知并固定 u 场时求解上面式子关于 v 场的最小化问题是一个 convex 的问题,可以通过传统的非线性优化方法来求解得到;然后已知并固定 v 场,求解上面式子关于 u 场的最小化问题就变成只跟 u 有关的问题,没有平滑项了,这时求解上式关于 u 场的最优化问题就用到了 PatchMatch 的思路,而不是 F. Steinbrucker 原文中的 brutal force 的方式,来寻求此时最优的 u 场;就这样求 u 场和求 v 场的两个各自全局最优化过程交替进行,并且每轮迭代后增加 sita 的值,当 sita 趋向于无穷时,上式的能量函数就和传统的能量函数一致了,而两个参数场 u 和 v 也趋向于相等了。
我得说这篇文章虽然直到现在才看懂,但是其思路真的非常不错,通过 Quadratic relaxation 完成 data term 和 smoothness term 的解耦,将能量函数全局最优问题拆成两个独立的优化问题,并交替进行直到收敛,真是不错。
8. Large Displacement Optical Flow Computation without Warping (completely read on 29th Jun 2014).
这篇文章就是文献【7】中借鉴的思路的出处,原文中其实是用 quadratic relaxation 来解耦一个 optical flow estimation 的能量全局最优问题,然后现在就被文献【7】用到了 Binocular stereo 当中,我相信这只是一个开始。
9. Real-Time Visibility-Based Fusion of Depth Maps (completely read on 7th Jul 2014).
Paul Merrell 在 2007 年的一篇 ICCV 文章,总的来说这篇文章看起来很费力,其中很多标示符和名词都有出现前后意思矛盾的情况,条理也不够清晰,看起来特别的费劲。
文章提出的算法是一种 multi-view stereo 算法,输入一堆图像,为每一幅图像选择 4-10 幅支持图集,并以此估计相对于参考图的深度图,其估计深度的方法主要是所谓的 plane-sweeping 方法,虽然不清楚具体做法,但可以肯定的是它是对深度有离散的,并且遍历了所有离散深度,并最终选取匹配代价最小的深度,而且可以肯定是每个像素处所有离散深度处的匹配代价是有内存记录的,因为文中要基于下式利用所有的匹配代价来计算选取深度的置信程度。也就是说每个深度图中的每个深度值都有对应的置信度。该置信度表征了对应深度值的单峰程度,要是单峰程度高的话说明该深度为最优的可能性越大。

在有了所有的深度图和置信度图之后,就开始进行其所谓的 visibility-based depth map fusion 了,文中提出的 fusion 方法有两种,一种是 stability-based fusion,一种是 confidence-based fusion。如左下图所示,文中将两个深度图之间可能存在的关系概括为三种,一种是 free-space violation,如图中 A 和 A' 的情况,一种是如 B=B' 所示深度相符合,另一种是如 C 和 C' 的情况,即 occlusion。

文中虽然声明了其 stability-based fusion 并不是简单的中值滤波,但我看完之后其实就是中值滤波,他将所有支持图集的深度图 render 到参考图中,然后选择所谓的 closest stable depth 作为最终的深度,按照 stable 的定义可以认为绝大多数情况下其最终选的深度就是中值深度,只不过他这里要把 free-space violation 和 occlusion 的概念给用上。
然后文中的 confidence-based fusion 可以认为就是利用了 confidence 加权的一个深度加权均值。
10. Scale Robust Multi View Stereo (completely read on 8th Jul 2014).
Christian Bailer 2012 发表的一篇 ECCV 文章,本文算法的一个重要特点就是可以 handle huge unstructured image datasets,也就是说可以同时利用不同空间分辨率(或者图像采样率抑或是尺度)的图像来进行 MVS,其算法的各个环节都有考虑利用到了图像尺度的信息,不仅仅是在一开始选择支持图集的过程中,还有后续深度融合的过程中。
首先,文中算法的总体流程是标准的 MVS 流程,即首先为每一幅输入图像通过一定机制选择多幅合适的支持图像组成支持图集,然后利用该支持图集通过核心的 MVS 算法生成相对于该参考图的深度图,重复该过程为每一幅输入图像生成深度图,之后再利用已有的初始的各深度图进行相互比较来去除 outliers 和进一步优化。
一、Image Selection. 文中选择支持图集是要基于稀疏特征匹配的结果,详细算法见文章,总之其选择算法要达成的效果就是使得支持图集与参考图之间的视线夹角较 Goesele 的方法更大,但又不会造成尺度差异太大;
二、Depth Map Creation. 其深度图生成的过程采用的是 PatchMatch 的机制,最有意思的一点是其综合 NCC 评分定义,如下所示,是一种 self-weighted score,可以自适应的抑制小 NCC 值对最终综合评分的影响,即文中所称的 occlusion robust and performed even at non-occluded surface parts better than a common weighting。

由于文中采用了上述的 self-weighted score,因此其在考察综合评分时,没有按照一定的 NCC 阈值来完全屏蔽低 NCC 值对深度评价的影响,因为作者认为用上述综合评分已经可以自适应的抑制低 NCC 值(即可能的 occlusion)的影响了,因此考察某深度值时,总是用的所有支持图像来进行的匹配,之后为了剔除仍然可能存在的误匹配,文中算法首先把那些存在误匹配(即 NCC 低于一定值)个数超过一定阈值的深度给剔除掉,然后还利用深度连接性对深度图进行分割聚类,将那些少于 15 个深度点的区域当作 outliers 给剔除掉。
三、Multi Depth Map Filtering. 这一步就是利用上面为每一个图像生成的深度图来进一步剔除 outliers,他这里的 filtering 利用到了上一篇文献中提到的 free-space violation 和 occlusion 的概念,连图都搬过来了,只不过他这里只用这些概念来剔除 depth values 即 filtering,不是用来做 depth fusion 或者优化。这一步里面剔除那些下式值小于 1 的 depth values,其中 rb 常数文中定义为 2。
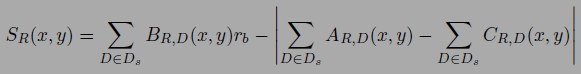
四、 Point Selection and Optimization. 这一步里面文中利用每个深度图的焦距和深度值为每个深度值对应的空间点分配了一个作用半径以及尺度值,就相当于误差椭球吧,然后先是选择那些作用半径里没有更小作用半径的空间点为所谓 primary point,并声明这些 primary points 代表了它附近拥有最优分辨率的点,因此也最有可能是精度最高的空间点,然后文章再利用每个 primary point 邻域内相同尺度的点来沿其法向迭代优化其位置及法向,详细过程见原文。
五、Meshing. 这一步里面文中采用到了 Delaunay Graph Cut 来做 meshing,原文为 Robust and efficient surface reconstruction from range data,值得看一下。
这是德国 University of Bonn 的 Dirk Holz 和 Sven Behnke 在 2013 年第 12 届 intelligent autonomous systems 大会上发表的一篇文章。
我其实是在 Point Cloud Library (PCL) 的 Surface extraction 模块的文档介绍中看到该文章的,因为 PCL 的 surface 模块里有一个函数 pcl::OrganizedFastMesh< PointInT > 就是实现的该文的算法。
正如本文题目中申明的那样,其最主要的目的是对深度图进行分割和平滑,我看本文主要的目的是看他里面如何对 organized point cloud (e.g. range image) 进行快速 mesh。文章的第 2 大节中把 range image segmentation 方法分为 3 大类:RANSAC, 3D Hough transform and region growing,作为了解。
直奔我最关心的 fast approximate meshing,其实我认为文中关于这部分的描述有问题,每次少考虑了邻域中的一个像素,关于我自己对 fast approximate meshing 的理解在笔记本里有详细叙述。然后关于其算法中如何快速求 mesh 中每个 vertex 的法向,以及后续如何对每个 vertex 的位置及其法向利用其与邻域 vertices 之间位置、法向以及颜色的邻近程度来进行 bilateral filtering 也一概在笔记本中有详细描述。
2. Occluding Contours for Multi-View Stereo (completely read on 8th Jun 2014).
本文是 Qi Shan, B. Curless, Y. Furukawa 以及 S. M. Seitz 在 2014 年的一篇文章。
3. Accurate Multiple View 3D Reconstruction Using Patch-Based Stereo for Large-Scale Scenes (completely read on 16th Jun 2014).
这篇文章是 SWJTU 的一位校友 Shuhan Shen 于 2013 年发表在 IEEE TRANSACTIONS ON IMAGE PROCESSING 上一篇文章,该校友 06 年于 SWJTU 毕业,之后于 10 年又拿到了 SJTU 的博士学位,现就职于北京中科院模式识别自动化所。
这篇文章的思路对于我来说还是很清晰的,该算法也是输入一堆图像,然后输出是为每个输入图像生成了一幅深度图,他的算法主要分成以下 4 步骤:
一、Stereo Pair Selection. 首先为每一幅图像选择一幅支持图像,文中将支持图像称为 reference image,whatever,选择的准则就是两幅图之间要有相似的视线角,以及不能太宽(重合区域少)也不能太窄(重建精度低)的基线,具体方法参考原文,总之其同时考虑了视线夹角以及基线长度;
二、Depth-Map Computation. 这一部分是该文最核心的部分,与当前我的方法中采用深度梯度来表示表面法向的方式不同,该文中采用的是真正的空间平面解析表达式的形式,当时我认为要解析的表示出该空间平面需要多于两个自由度的参数,但是却从未想过可以把平面放到像机坐标系下用两个球体极坐标来表示,这样平面法向参数表示也就是两个自由度了。有了空间平面的解析表示后,就可以通过空间平面诱导出两图像间的单应了,匹配像点之间的转移也更为简单(左乘诱导单应)。其后的过程我已经很熟悉了;
三、Depth-Map Refinement. 这一部分其实就是利用我的方法中 depth consistency check 来剔除 outliers;
四、Depth-Map Merging. 这一步中作者要做的是把匹配的很多冗余量给剔除掉,但实际上这样做损失了精度,没有将冗余观测利用起来提高重建精度。
4. Quasi-Dense 3D Reconstruction using Tensor-Based Multiview Stereo (completely read on 18th Jun 2014).
这篇文章是香港科技大学 (HKUST) Tai-Pang Wu 2010 年的一篇 CVPR 文章,文献【3】的 Introduction 中有介绍该文章,所以就下下来看了。
该文方法基于 PMVS 的主体框架,在其各个环节中引入 Tensor Voting 机制以优化得到更准的法向估计和坐标,以及更好的剔除 outliers。
关于 Tensor voting 可以参考 T. P. Wu 2012 年的 TPAMI 文章。
该文方法主要将 Tensor voting 用到了 PMVS 的一下 3 个环节:
一、Match. 也就是 PMVS 中对 features 进行稀疏重建的环节,这个环节中 tensor voting 的介入有两种情况,一种是当图像未标定的时候,也就是内定向及外定向未知时,这时候一般的做法是进行 SfM 通过 RANSAC 来先估计两视图间的基础矩阵同时进行特征匹配,而本文提出一种基于 Expectation-Maximization 参数估计方法的 EMTV 算法可以用来同时估计基础矩阵和进行匹配,是类似于 RANSAC 的一种鲁棒方法,据文中给出的结果 EMTV 方法得到了更好的稀疏重建结果;另一种情形就是当图像完成了标定的时候,这时候 TV 可以用来优化稀疏重建的 patches 的法向,做法就是每个 patch 都收集其邻近的 patches 的张量,得到其更新的张量,并从中得到新法向,以下是经过 TV 前后的法向重建结果对比;
二、Propagation. PMVS 原文中的做法是根据已经存在的 patches 的法向和邻域先生成一系列候选的三维点位,然后沿每个候选点的视线方向去优化该候选点的法向和位置。本文方法也将 TV 应用在了这一环节中,具体点就是应用在了候选点法向和位置的优化上,它是怎么去优化的呢,首先也是沿着候选点的视线方向去调整采样,并记录每个采样位置处的 photoconsistency (NCC) 程度和 surface saliency 程度(邻域内对该采样位置处的 TV),并定义了如下的一个同时考虑了photoconsistency 和 surface saliency 的综合指标,并最终选择拥有最优该指标的采样位置和得到的法向作为最终优化值;
三、Filtering. 这一步里面作者用其所谓的 MRF-TV 来进一步剔除 outliers,详见原文。
5. A Closed-Form Solution to Tensor Voting: Theory and Applications (completely read on 19th Jun 2014).
上文作者 Tai-Pang Wu 于 2010 年发表在 TPAMI 上的一篇详细介绍其 CFTV 原理的文章,里面有一些思路很巧妙的地方,尤其是给定一个位置上的法向,如何推断指定点位上的最有可能的法向,其实 Tensor voting 的思想最早是由 University of South California 的 Gerard G. Medioni 教授提出来的,只不过在 CFTV 之前的 TV 应用都是先要计算一些 precomputed tensor fields,也就是说是数值的形式,而这里 CFTV 是闭合的解析的形式,计算点 j 处张量 Kj 在点 i 处的投票直接使用如下式子,而无需再事先计算 precomputed voting fields 了,其实关于其中的积分公式我有详细的笔记和解读。
6. Combined Depth and Outlier Estimation in Multi-View Stereo (completely read on 24th Jun 2014).
C. Strecha 2006 年的一篇 CVPR,很早之前就尝试着看过一两次,但都没有看太明白,主要是对其中采用的 Expectation-Maximizaiton 思想不太明白,但是最近自学了参数估计里的 MLE, MAP, Bayesian Estimator 和 EM 算法之后,现在终于算是明白这篇文章的方法了,该文中的方法思路还是非常有创造性的,详细的理解和解读在笔记当中有。
7. PM-Huber: PatchMatch with Huber Regularization for Stereo Matching (completely read on 29th Jun 2014).
这是慕尼黑工业大学的 P. Heise 在 2013 年发表的一篇 ICCV 文章,文章的方法还是 Binocular stereo 方法,需要对两视图进行图像矫正,考虑的还是视差,另外其采用的 support window model 依然是 M. Bleyer 2011 年文章中的模型,即 disparity space plane model,只不过本文中对 window 中像素在两视图中的转移公式用单应解析的表示出来了。
可以这么说吧,本文并不是我一开始设想的是在原 PatchMatch 的框架中加入了 smoothness 项,然后最终结果可以达到能量函数全局最优的这么一种方式,本文的方法实际上应该是早就有了一个分步交替求解全局最优的框架,只不过其中的一步原本涉及到 brutal force searching 本文就想到了用 PatchMatch 来代替原来的 brutal force searching 提高计算速度。
本文最核心的思路就是借鉴了 Frank Steinbrucker 2009 年在 ICCV 的文章 Large Displacement Optical Flow Computation without Warping 中的思路,就是把传统的能量函数通过使用 Quadratic relaxation,即添加一个 auxiliary parameter field 构成一个 quadratic term 将之前的耦合在一起的 data term 和 smoothness term 解耦成两个独立的优化问题,如下式所示。
其中 u 和 v 是两个参数场,每个像素都包含了视差和法向参数,已知并固定 u 场时求解上面式子关于 v 场的最小化问题是一个 convex 的问题,可以通过传统的非线性优化方法来求解得到;然后已知并固定 v 场,求解上面式子关于 u 场的最小化问题就变成只跟 u 有关的问题,没有平滑项了,这时求解上式关于 u 场的最优化问题就用到了 PatchMatch 的思路,而不是 F. Steinbrucker 原文中的 brutal force 的方式,来寻求此时最优的 u 场;就这样求 u 场和求 v 场的两个各自全局最优化过程交替进行,并且每轮迭代后增加 sita 的值,当 sita 趋向于无穷时,上式的能量函数就和传统的能量函数一致了,而两个参数场 u 和 v 也趋向于相等了。
我得说这篇文章虽然直到现在才看懂,但是其思路真的非常不错,通过 Quadratic relaxation 完成 data term 和 smoothness term 的解耦,将能量函数全局最优问题拆成两个独立的优化问题,并交替进行直到收敛,真是不错。
8. Large Displacement Optical Flow Computation without Warping (completely read on 29th Jun 2014).
这篇文章就是文献【7】中借鉴的思路的出处,原文中其实是用 quadratic relaxation 来解耦一个 optical flow estimation 的能量全局最优问题,然后现在就被文献【7】用到了 Binocular stereo 当中,我相信这只是一个开始。
9. Real-Time Visibility-Based Fusion of Depth Maps (completely read on 7th Jul 2014).
Paul Merrell 在 2007 年的一篇 ICCV 文章,总的来说这篇文章看起来很费力,其中很多标示符和名词都有出现前后意思矛盾的情况,条理也不够清晰,看起来特别的费劲。
文章提出的算法是一种 multi-view stereo 算法,输入一堆图像,为每一幅图像选择 4-10 幅支持图集,并以此估计相对于参考图的深度图,其估计深度的方法主要是所谓的 plane-sweeping 方法,虽然不清楚具体做法,但可以肯定的是它是对深度有离散的,并且遍历了所有离散深度,并最终选取匹配代价最小的深度,而且可以肯定是每个像素处所有离散深度处的匹配代价是有内存记录的,因为文中要基于下式利用所有的匹配代价来计算选取深度的置信程度。也就是说每个深度图中的每个深度值都有对应的置信度。该置信度表征了对应深度值的单峰程度,要是单峰程度高的话说明该深度为最优的可能性越大。
在有了所有的深度图和置信度图之后,就开始进行其所谓的 visibility-based depth map fusion 了,文中提出的 fusion 方法有两种,一种是 stability-based fusion,一种是 confidence-based fusion。如左下图所示,文中将两个深度图之间可能存在的关系概括为三种,一种是 free-space violation,如图中 A 和 A' 的情况,一种是如 B=B' 所示深度相符合,另一种是如 C 和 C' 的情况,即 occlusion。
文中虽然声明了其 stability-based fusion 并不是简单的中值滤波,但我看完之后其实就是中值滤波,他将所有支持图集的深度图 render 到参考图中,然后选择所谓的 closest stable depth 作为最终的深度,按照 stable 的定义可以认为绝大多数情况下其最终选的深度就是中值深度,只不过他这里要把 free-space violation 和 occlusion 的概念给用上。
然后文中的 confidence-based fusion 可以认为就是利用了 confidence 加权的一个深度加权均值。
10. Scale Robust Multi View Stereo (completely read on 8th Jul 2014).
Christian Bailer 2012 发表的一篇 ECCV 文章,本文算法的一个重要特点就是可以 handle huge unstructured image datasets,也就是说可以同时利用不同空间分辨率(或者图像采样率抑或是尺度)的图像来进行 MVS,其算法的各个环节都有考虑利用到了图像尺度的信息,不仅仅是在一开始选择支持图集的过程中,还有后续深度融合的过程中。
首先,文中算法的总体流程是标准的 MVS 流程,即首先为每一幅输入图像通过一定机制选择多幅合适的支持图像组成支持图集,然后利用该支持图集通过核心的 MVS 算法生成相对于该参考图的深度图,重复该过程为每一幅输入图像生成深度图,之后再利用已有的初始的各深度图进行相互比较来去除 outliers 和进一步优化。
一、Image Selection. 文中选择支持图集是要基于稀疏特征匹配的结果,详细算法见文章,总之其选择算法要达成的效果就是使得支持图集与参考图之间的视线夹角较 Goesele 的方法更大,但又不会造成尺度差异太大;
二、Depth Map Creation. 其深度图生成的过程采用的是 PatchMatch 的机制,最有意思的一点是其综合 NCC 评分定义,如下所示,是一种 self-weighted score,可以自适应的抑制小 NCC 值对最终综合评分的影响,即文中所称的 occlusion robust and performed even at non-occluded surface parts better than a common weighting。
由于文中采用了上述的 self-weighted score,因此其在考察综合评分时,没有按照一定的 NCC 阈值来完全屏蔽低 NCC 值对深度评价的影响,因为作者认为用上述综合评分已经可以自适应的抑制低 NCC 值(即可能的 occlusion)的影响了,因此考察某深度值时,总是用的所有支持图像来进行的匹配,之后为了剔除仍然可能存在的误匹配,文中算法首先把那些存在误匹配(即 NCC 低于一定值)个数超过一定阈值的深度给剔除掉,然后还利用深度连接性对深度图进行分割聚类,将那些少于 15 个深度点的区域当作 outliers 给剔除掉。
三、Multi Depth Map Filtering. 这一步就是利用上面为每一个图像生成的深度图来进一步剔除 outliers,他这里的 filtering 利用到了上一篇文献中提到的 free-space violation 和 occlusion 的概念,连图都搬过来了,只不过他这里只用这些概念来剔除 depth values 即 filtering,不是用来做 depth fusion 或者优化。这一步里面剔除那些下式值小于 1 的 depth values,其中 rb 常数文中定义为 2。
四、 Point Selection and Optimization. 这一步里面文中利用每个深度图的焦距和深度值为每个深度值对应的空间点分配了一个作用半径以及尺度值,就相当于误差椭球吧,然后先是选择那些作用半径里没有更小作用半径的空间点为所谓 primary point,并声明这些 primary points 代表了它附近拥有最优分辨率的点,因此也最有可能是精度最高的空间点,然后文章再利用每个 primary point 邻域内相同尺度的点来沿其法向迭代优化其位置及法向,详细过程见原文。
五、Meshing. 这一步里面文中采用到了 Delaunay Graph Cut 来做 meshing,原文为 Robust and efficient surface reconstruction from range data,值得看一下。
订阅:
评论 (Atom)