1. Fast Cost-Volume Filtering for Visual Correspondence and Beyond (Completed read on 16th Dec. 2014).
Asmaa Hosni和Michael Bleyer 2013年在TPAMI上发表的一篇Short paper,现在的引用已经有四十几次了。本文提出的Fast Cost-Volume Filtering方法是一种可以用于stereo、optical flow以及分割的一类通用方法,如果用于stereo,那么就成了一种local binocular stereo方法,具体做法就是首先构建匹配代价空间,也就是Disparity Space Image (DSI),然后对DSI中的每个视差层的每个像素进行加权滤波,最后在滤波后的DSI中采用Winner-Takes-All策略为每个像素选定最优视差值。
Yoon and Kweon提出的Adaptive Support-Weight (ASW)方法说白了其实也就是这么一种在Cost-Volume进行滤波然后WTA选择视差的流程,只不过Yoon and Kweon没有从Cost-Volume Filtering的角度来阐述他们的方法,而是从support weight的角度来阐述的,且ASW用的是Bilateral filtering,这篇文章里采用的是guided filtering算法,即用参考图为guidance image来计算权值,说是可以用integral image方法来快速实现,从而使其运算量与窗口大小无关。
本文的方法已经可以以很高的帧率来进行实时视差图估计了,精度也不错,值得深入学习,现在里面采用的guided filtering的原理还需要进一步学习一下,只知道它的加权方式和bilateral filtering的方式不太一样,bilateral里的权值跟像素间的距离以及色彩差有关,而这里的guided filtering就涉及到窗口的色彩均值以及协方差阵,接下来就看介绍guided filtering的原文献。
2. Automated Target-Free Network Orienation and Camera Calibration (Completed read on 21th Dec. 2014).
这就是Christos和Clive今年六月份在意大利参加ISPRS会议的时候发表的文章,内容就是关于iWitness在不使用人工标志的情况下如何利用自然图像特征来进行自动化的相机网络定向。
文章算法的流程分为5大步:
一、先提取每幅图像上的特征点,并且通过FLANN (Fast library for approximate nearest neighbors)最近邻算法来获得图像对之间的初始的特征点匹配,FLANN算法是Muja和Lowe提出的,里面有针对vector-based features (SIFT, SURF)的最近邻匹配搜索算法,也有针对binary-valued features (BRIFF, ORB and FREAK)的最近邻匹配搜索算法;
二、图像对之间特征点对应的refinement,这一步又分为4小步,首先就是要求一个特征点的最优匹配的匹配距离最多只有次优匹配的匹配距离的30%,否则这种点对应就被取消掉了;上一步之后,还是会存在一对多的匹配情况,因此第二步就是强行只保留那些一对一的点匹配,滤除掉任何一对多的点匹配;第三步是构建一个二维的统计直方图,一维是特征描述的半径,一维是特征描述的旋转,构建好直方图之后,滤除掉那些和大多数匹配特征描述不一致的点匹配;最后一步就是基于基础矩阵的RANSAC方法了,文章用的是Nister (2004)的5点算法,文章说这里的RANSAC可以应对最多50% outliers的情况,前面几步的filtering就是为了减少这里RANSAC时的outliers;
三、识别添加更多的点匹配,上一步中的第一步过滤利用到了最优匹配和次优匹配的匹配距离,滤除了很多有可能正确的匹配,这里利用已经RANSAC估计得到的基础矩阵来检验这些匹配中哪些是可以恢复为正确的,这里同时检验最优匹配和次优匹配,只有当最优匹配和次优匹配中的其中之一满足对极几何时才会被恢复采纳,否则还是会被弃用,因为如果最优匹配和次优匹配都满足对极几何将无法得知哪个才是真正的匹配。这一步骤能够恢复很多点匹配;
四、Epipolar Mismatch Filtering,这一步具体还是参见原文的描述,我没有看太明白,我的理解是多个匹配在两幅图像上的拓扑关系应该是可以用一个所谓的projective transformation描述的,从左图到右图用一个这样的转换关系描述一次,不满足该描述的点被标记了,然后从右图到左图再描述一次,要是已经被标记的点依然不满足该描述那么该匹配就被剔除掉了,目前的理解就是这样,详细的过程可以请教Christos;
五、Network orientation,文章算法里的Relative orientation并不是仅仅选择在拥有最多点匹配的图像对之间去做,而是选择的在拥有最多multi-ray点匹配的图像对之间去做,这样将使得在需要进行前方交会之前有最多可能的图像通过后方交会的方式定向好。
3. Fully Automated Image Orientation in The Absence of Targets (Completed read on 23th Dec. 2014).
这就是Christos和Clive 2012年墨尔本八月底ISPRS大会上投的稿,上一篇文献是对本文的一个补充和总结。因此方法论这一块应该是上一篇文章里描述的更为准确详细,这里就摘录一些本文的文字叙述吧,前言部分提到有其它文章已经阐述了基于自然图像特征的匹配精度能达到0.3个像素的样子,也有人尝试过在特征匹配的基础上进一步跟进一次最小二乘匹配,精度大概能提高到0.25个像素的样子,提升不明显,因此本文作出了图像特征匹配精度很难再进一步提升的论断。文章阐述了在对wide baseline图像进行匹配的时候,为了保证能有足够多的特征点参与匹配,在特征检测的过程中最好不要强加很强的响应阈值,或者说直接不加任何响应阈值,以获得足够多的特征点,否则在大基线的情况下因为基线或者会聚角一大特征点的相似性就下降了本来能配上的点就少,要是一开始检测到的能够来参与匹配的特征就少那更加影响匹配的成功率。
这篇文章对上文中利用projective tranformation剔除匹配outliers进行了详细的描述,我的理解是该算法先对左图中提取出来的一系列图像特征点进行二维的迪罗尼三角网格化,然后利用得到的一个个三角形的三个点去和对应的右图上的匹配的三个点估计一个之间的仿射变换参数,并对各估计的仿射参数在参数空间内进行聚类,拥有较少元素的聚类被认为是一些孤立的参数集,它们联系的图像点的匹配就被当作outliers剔除掉,这是利用三角网格估计仿射变换参数的方式,文中还描述了利用四边形网格估计射影变换参数的方式,并通过实验说明射影变换的方式更优于仿射变换的方式,因为仿射变换仅仅适合于小图像区域的情形,不能描述大图像区域的情形,利用文中构建四边形网格的方式是在上述三角形网格的基础上拆掉相邻三角形的共有边来构建的四边形网格。
4. A Public System for Image Based 3D Model Generation (Completed read on 26th Dec. 2014).
这篇文章是ARC3D http://www.arc3d.be/ 提供的两篇参考文献之一,作者为David Tingdahl和Luc Van Gool (SURF的作者之一),发表于2011年。
在文章的previous work中提到ARC3D在2005年就已经上线运行,至今已经有9个年头了,堪称所有在线三维重建服务的鼻祖。同样的服务还有微软的PhotoSynth以及最近的3dTubeMe。
ARC3D的重建流程为:
一、首先对用户上传的图像内参数进行预标定,一般头像的EXIF数据中会包含有物理焦距信息,但是不一定包含像元尺寸信息,这时系统就在互联网上自动的搜索像机的像元尺寸参数,有了这两个信息之后就可以得到大致的等效焦距信息;
二、在每一幅图像上提取SURF特征点,并且为每个图像对进行特征点匹配,对于两幅图像都预先有内参数初值的,采用5点算法RANSAC计算本质矩阵来匹配,否则就采用7点算法RANSAC计算基础矩阵。
三、自标定,这是可选步骤,如果所有输入图像中少于两幅图像预先知道内参数,那么就采用Web-based 3D reconstruction service (ARC3D提供的另外一篇参考文献)一文中描述的自标定算法来标定内参数,但是这种方法在图像内参数不恒定,以及像机运动(turntable motion)和场景结构不够general (为平面)时会失效;
四、稀疏重建,为了保证足够的基线,通过检查两幅图像之间的关系是否可以很好的用一个无穷单应(infinite homography)来描述来判断两幅图像是否有足够长的基线,如果可以就说明两图像的基线太短,这一方法在3D Reconstruction from Multiple Images: Part 1 - Principles一文中有详细描述,每个新加入的图像通过3个已有的重建点进行后方交会来确定外定向,并且跟进光束法平差优化,平差的参数有6个外定向参数、一个等效焦距值以及2个径向畸变系数;
五、密集重建,稀疏重建结果被用来初始化密集重建,利用已得到的图像定向关系,将所有重叠的图像串成链条,然后进行极线矫正,并采用基于动态规划的dense stereo算法来估计视差图(Visual Modeling with a Hand-Held Camera)。Stereo pairs被串成链,并且每个像素的最优深度通过Kalman滤波跟踪出来。密集重建方法同时还提供质量图,每个像素估计的质量通过正确匹配上的图像个数来表征。
文章中提出了一种view selection策略来从所有的深度图中只选择若干幅来进行后续的meshing,这样做的理由的是很多的图像之间有大量的重叠区域会导致meshing过程中大量不必要的计算量,再者就是低质量的深度图也参与meshing的话会导致meshing的质量下降。很显然这里的view selection和之前我了解的那个view selection指的不是一个意思,一般view selection是指的在密集重建时基于某种准则为参考图像选择若干合适的匹配图像。这里为meshing的view selection的准则是尽可能减少overlap的同时要尽可能多的cover整个重建场景,还有就是倾向于选择高质量的深度值参与meshing。文章里判断coverage时不是用的密集点,而是用的稀疏重建点去判断的。
在真正做meshing之前,先对所有的深度图进行剔除outliers的操作,有3步骤,首先删除那些少于三幅图像观测到的深度图的像素,接着按深度聚类,只保留最大连通的深度区域,其它的像素全部删除,最后做一个腐蚀操作,剔除掉深度边界可能的噪声深度点。之后文章还有一步所谓的Depth map to 3D,将深度图反投影至空间中,并通过连接邻近点得到一个粗糙的mesh,剔除那些法向和光轴夹角太大的triangles,以及那些最短边比最长边短两倍以上的triangles。上两步之后,就是用的Poisson表面重建方法来做真正的meshing,格网之后,剔除那些拥有边长比所有网格边平均长度还长5倍的triangles。
形成mesh之后,要为mesh应用纹理,也就是为mesh里的每个faces着色,我看他们的做法是为face在每个图像里做frustum culling(遮挡判断),看face在哪些图像里可见,然后选择可见图像中投影面积最大的那幅图像里的颜色信息来为该face着色。
5. Web-Based 3D Reconstruction Service (Completed read on 28th Dec. 2014).
这篇文章就是ARC3D http://www.arc3d.be/ 提供的另一篇参考文献,作者为Maarten Vergauwen和Luc Van Gool,发表于2006年。
文章里更为详细的描述了他们的系统里是如何为每幅图像计算密集深度图的,算法主要流程分为4大步骤:
一、判断哪些图像对可以用来进行匹配,包括降采样以及Global Image Comparison两步,这个全局图像比较其实就是判断个两图间的相似性;
二、先为上一步中得到的所有图像对进行特征匹配,然后选择若干组三视图组进行射影重建,并基于此进行像机自标定,得到图像的内参数;
三、欧氏重建以及将深度图upscale至原分辨率;
四、密集重建。
文章的算法一开始就对所有的输入图像降采样至最大1000×1000的图像,然后后续操作在upscale之前全都是在这些小分辨率的图像上去做。
这篇文章涉及的内容还比较多,详细的阐述这里就不复述了,还是参见原文,他里面的Global Image Comparison方法还有点意思,是将所有图像进一步降采样至最大只有100×100,然后直接通过平移窗口在两视图间去算NCC去判断的相似性的,有点意思。
6. Where is photogrammetry heading to? State of the art and trends (Completed read on 16th Feb. 2015).
这是2015年最新出来的一篇综述性的文章,文章里就Image orientation, surface reconstruction and object restitution三个基本方面对Photogrammetry和Computer vision进行了对比。
文章里出现了Automatic block orientation这个术语,block orientation具体指的什么意思我没有看太明白。文章里还较为详细的描述了在三视图参与匹配时如何剔除误匹配,其中提到了一种data snooping的local bundle solution方法,这个方法是我接下来要去学习的内容。
之后文章中又出现一个Bundle block adjustment的术语,这个block在这里指的什么,这个光束法平差和我知道的光束法平差的差异在哪里我也不太清楚。文章提到CV领域在做光束法平差时往往采用LM算法,而摄影测量领域往往采用Gauss-Newton方法,另外CV领域做BA一般不用Ground control points,而摄影测量领域则有GCPs,文章说BA里不用GCPs的话会产生block deformations,且image orientation的好坏不能仅从重投影残差来看,还得使用check points,这些个情况也是我需要进一步了解的,我一直认为BA过程中不需要控制点,只需要固定某一个图像的坐标系即可,其它的全部可以自由平差。
7. Orientation and 3D Modelling from Markerless Terrestrial Images: Combining Accuracy with Automation (Completed read on 20th Feb. 2015).
这篇文章以及接下来的两篇文章都是上一篇文献中介绍data snooping时列出来的参考文献。该文是Luigi Barazzetti于2010年在The Photogrammetric Record上发表的一篇期刊文章。
文章提出的方法主要是针对利用calibrated cameras拍摄的图像来进行三维重建,并且提到在weak image network的时候最好避免self-calibration(自检校),可以想象在image network不好的时候进行自检校光束法平差出来的重建结果不可靠,因为自检校光束法平差时内外参耦合严重,外参数的一部分误差可能会融入到内参数误差里,即使最终残差会少不少。
文章方法的第一步也是检测SIFT或者SURF特征点,然后通过描述子来进行特征匹配,第三步就是利用基于epipolar geometry的robust techniques来大量剔除匹配outliers,当图像内定向未知时该对极几何用基础矩阵F表示,内定向已知时则可以考虑用本质矩阵E表示,并通过Nister(2004)提出的5点算法来求解,文中介绍了3种robust techniques: RANSAC, LMedS (least median of squares) and MAPSAC (maximum a posterior sample consensus),并介绍了3种方法各自的优缺点,并指出MAPSAC的使用能带来significant solution improvement。
接下来文中方法采用最小二乘匹配(LSM)来进一步提高各匹配同名像点的定位匹配精度,虽然文中没有明确说明,但是既然要使用LSM,那么肯定是以某一个图像里同名像点为中心抠出来了一块参考窗口,并在其它各匹配图像中去做LSM的。
文中还引用了Clive 96年的一篇文章里的一个根据像点提取精度来推算重建空间点精度的经验公式,并以此出发提到图像特征被越多的图像观测到会带来越高的稀疏重建精度以及图像定向精度。因此在上述步骤之后,文中方法进一步在每一幅图像上提取FAST角点特征,因为FAST相对于SIFT和SURF有着更高的repeatability and better distribution in the images。提取的FAST特征点是通过基于collinearity geometry的multi-image constrained LSM来进行匹配的,这一步骤我没有太明白到底是怎么做的,文中指出points are projected onto the images,难道是先交会出来?但是交会的时候怎么识别误匹配呢?文中没有说对FAST特征点也去生成特征描述并进行特征描述匹配,我自己想了下一个可行做法就是每个图像里的每个FAST特征点都在其它图像中去做LSM,但这样做似乎又不是文中所说的multi-image constrained LSM,所以这一块具体是怎么做的我还没有理解太透彻。
完成所有图像的定向之后就是进行文中所谓的surface measurements,也就是相当于密集表面重建吧,但是经过我的反复阅读,我认为文中方法并不是企图为每幅图像的每个像素都估计一个深度和法向,按我阅读后的理解,他应该是这么去做的,首先也是建立了金字塔,即为每幅图像生成了不同分辨率的金字塔图像,在每一层都进行了以下步骤:在图像上划分均匀的image grid,每个格子里都提取了 Lue interest points,每个interest points的初始深度和法向估计通过多个邻近的在之前网络定向环节得到的稀疏点来插值得到,然后以该interest point为中心,抠一块矩形区域来按当前法向沿深度方向上去移动,并与其它多个匹配图中重采样出来的窗口去计算NCC值,并取所有NCC值之和(SNCC)最大的深度为该interest point处当前最优的表面深度估计,这整个过程被称为 geometrically constrained cross-correlation (GC3),调整的应该只有深度,而没有法向,但不知道作者是怎么去调整深度的,是等间隔采样还是怎么着?也不清楚window warping是基于什么模型去做的,即一个窗口里对应的空间surface是通过几个什么参数来描述的,这些文中都没有说清楚。
然后文中说利用MPGC LSM在原图分辨率上来进一步提高匹配精度,这里用的MPGC LSM是Gruen原始的方法,不知道该原始MPGC里面调整的参数有哪些,我觉得至少应该有沿点心射线上的深度值,然后作为一种表面估计方法,它里面是如何描述和调整表面法向的我还不太清楚,但我看到有一句话就是while the affine parameters converge during the iterations,难道参考窗口和每个匹配窗口之间的形变还是通过仿射模型来描述的?那每个不同匹配窗口岂不是都拥有自己不同的仿射参数?那优化的参数可就多了去了,anyway,我还是阅读完Gruen的原文后才能有发言权。
看完该文的密集表面重建方法,我感觉跟我自己的方法有相似的地方,但也还是有很多不同的地方。
8. Experiences and Achievements in Automated Image Sequence Orientation for Close-Range Photogrammetric Projects (Completed read on 22th Feb. 2015).
该文是Luigi Barazzetti于2011年发表的一篇SPIE的会议文章。相比上一篇期刊文章,这篇文章内容要精简很多,但也有些值得学习的点。
例如在提取图像特征(SIFT或者SURF)并完成匹配后,肯定会出现图像某些纹理丰富的区域提取出非常密的特征点,有些纹理弱一点的区域就只有非常稀疏的特征点,也就是说图像特征分布不是很均匀,那么文中方法就这么处理:先在图像划分均匀网格,每个网格里只保留multiplicity最高的特征点,也就是在最多图像上成功匹配的特征点,这样做的话就不会出现物方某一小块区域重建出大量的密集点,而有些区域只重建出少量点,就相当于光束法平差的时候某一块区域的物点的权重较大,而另一些区域的权重较小了,这也算是一种weak geometry吧。
文中还指出虽然在匹配环节通过基于对极几何的robust techniques能剔除掉大量的匹配outliers,但也没法完全确保光束法平差的时候百分之百的没有outliers,因此在多图光束法平差的时候还是有必要利用data snooping来在平差迭代过程中进一步剔除outliers。文中在实验结果中还列了一个重建结果,利用本文的方法由于在bundle迭代过程中剔除了几个wrong data使得最终成功的完成了所有图像的定向和稀疏重建。但是利用Autodesk Photofly以及Microsoft Photosynth处理同一组图像则都失败了,文中总结其原因就是most probably due to the repeated patterns in the scene and the employed bundle adjustment.
在讨论部分文章指出stability of the solution依赖于两类点:
1. tie points (TPs), which guarantee the precision of the orientation solution; they should be numerous, well distributed on the object and in the image space and they should feature a high multiplicity;
2. ground control points (GCPs), which have the role to fix the datum and to control the block deformation.
最后还指出SfM的精度依赖于tie points的measurement precision, multiplicity and spatial distribution.
9. Comparison of Two Structure and Motion Strategies (Completed read on 23th Feb. 2015).
该文是R. Roncella于2011年在International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences上发表的一篇文章。
题目中的两种SaM策略其实就是作者自己的一个软件中先后采用的两种策略,最新的策略和老策略的区别就在于新策略采用了SIFT和SURF这种图像特征以及匹配方式;第二个区别就在于利用基于epipolar/trifocal几何约束的robust techniques剔除outliers时,新策略充分利用了已知内定向的约束,比方说就是把之前鲁棒估计F换成了鲁棒估计E来剔除outliers,就这么简单,详细的过程可以参考原文,这里不再赘述了。
2014年12月15日星期一
2014年11月12日星期三
网购Tamron 24-70mm f/2.8 Nikon mount到货
周六凌晨在eglobal订购的Tamron 24-70mm f/2.8 Nikon mount今天终于是到货了,包装还算完好,但是感觉有点折痕,稍显旧,不知道是不是邮寄颠簸导致的。
 加邮费总共花销931澳币,折合人民币4925元,比国内网上报的均价还是能便宜到近一千元,看过网上的的测评,拿此副厂镜头和尼康的原厂24-70mm f/2.8镜头比也不输毫厘,在锐度上有时甚至更优,真是性价比非常高的一款镜头,只是目前手上还没有尼康的相机可以直接试试画质的,不知道这几天能找谁借个机身试一下不,看完画质才能最终放心下来。
加邮费总共花销931澳币,折合人民币4925元,比国内网上报的均价还是能便宜到近一千元,看过网上的的测评,拿此副厂镜头和尼康的原厂24-70mm f/2.8镜头比也不输毫厘,在锐度上有时甚至更优,真是性价比非常高的一款镜头,只是目前手上还没有尼康的相机可以直接试试画质的,不知道这几天能找谁借个机身试一下不,看完画质才能最终放心下来。

 镜身上赫赫的标着Made in Japan。
镜身上赫赫的标着Made in Japan。





2014年9月8日星期一
解决一个意想不到的问题
求两个法向的夹角,程序上自然是 cosa = n1'*n2/|n1||n2|,然后 a = acos(cosa),但是这两天在程序上遇到的问题是 n1=n2,也就是说夹角肯定为0,cosa=1,然而在算的时候却发现实际 cosa = 1.00000000000002,大于了acos()函数的[-1,1]的输入域,因此造成acos()返回了1.#IND00无效位,导致程序结果出现异常,真是没有想到会有这样的问题,我的猜测是OpenCV里用来算模的函数norm()里损失了精度,导致算的模偏小,因此出现了这种大于1的情况,无奈只能是自己加个判断把这种情况避免开,之后结果就正常了。
一些实用的小函数记录
int _finite( double x );
_finite returns a nonzero value if its argument x is not infinite; that is, if –INF < x < +INF. It returns 0 if the argument is infinite or a NAN.
int _isnan( double x );_isnan returns a nonzero value if the argument x is a NAN; otherwise it returns 0.
2014年8月30日星期六
SfM问题总结
1、20140831. 好久没有动过自己的SfM代码了,今天改进了一个地方,那就是RO的代码里之前没有判断两视图间匹配个数,导致有时两视图间根本没有任何有效匹配时,还去做RO,结果就导致程序直接报错退出了,现在改为至少得有3个有效匹配,采取做RO;
2、TempleRing的测试图中第1幅图的EO和第31幅图的EO基本一致,当把第31幅图考虑进来一起做SfM时,导致重建结果不对,一旦把第31幅图排除出去,SfM的结果就正确了,看来之前的SfM代码在这一块还需要改进;
3、之前我的SfM流程貌似有一个比较严重的问题,那就是貌似有效匹配图越多,好像找到的有效tracks越少,我在想这会不会是因为两视图间一一映射的约束太强,容易把还不错的tracks给误杀掉,总之看起来明显是有需要改进的地方。
2、TempleRing的测试图中第1幅图的EO和第31幅图的EO基本一致,当把第31幅图考虑进来一起做SfM时,导致重建结果不对,一旦把第31幅图排除出去,SfM的结果就正确了,看来之前的SfM代码在这一块还需要改进;
3、之前我的SfM流程貌似有一个比较严重的问题,那就是貌似有效匹配图越多,好像找到的有效tracks越少,我在想这会不会是因为两视图间一一映射的约束太强,容易把还不错的tracks给误杀掉,总之看起来明显是有需要改进的地方。
2014年8月1日星期五
2014年7月1日星期二
外婆
上午收到家里消息说外婆于昨晚去世了,因为外婆年事已高,而且最近几年身体一直不好,近期又查出肝癌晚期,所以早有心理准备,但看到消息的那一刻心里还是一惊,缓过神来才意识到外婆是真的离开我们了。
还记得我出国之前几天去小舅家看望外婆,发现外婆的头发较之前愈发花白,个子也更矮了,整个人微胖,显得憨态可掬,现在想想那可能只是身体不适导致的浮肿,我能感觉到外婆的身体状态不比以前,但当时的精神头还可以,却不曾想半年后的今天外婆就辞世了。
当时在小舅家待的最后一天晚上大家带着外婆一起去外面的馆子吃饭,吃完饭之后就要启程回株洲了,外婆一个人坐在餐馆的椅子上一边看着我和凤凤一边在抹眼泪,我还笑着安慰外婆说“别哭,这哭什么,我在国外也就待一年,很快就回来了”,外婆抹干了眼泪也笑着对我说“好,好,在外面注意安全”,现在才明白外婆当时就料到了自己可能挺不过这一年,不料那也真的成了我见外婆的最后一面,画面就这样永远的定格在了那一瞬,一个憨憨的小老太太坐在椅子上眼含泪水望着我和凤凤。
外婆总说我是她的骄傲,我也一定会更努力让她继续以我为傲,真心希望外婆在天国有一块温暖的地方,再无病痛和忧伤,唯有永远的阳光。
还记得我出国之前几天去小舅家看望外婆,发现外婆的头发较之前愈发花白,个子也更矮了,整个人微胖,显得憨态可掬,现在想想那可能只是身体不适导致的浮肿,我能感觉到外婆的身体状态不比以前,但当时的精神头还可以,却不曾想半年后的今天外婆就辞世了。
当时在小舅家待的最后一天晚上大家带着外婆一起去外面的馆子吃饭,吃完饭之后就要启程回株洲了,外婆一个人坐在餐馆的椅子上一边看着我和凤凤一边在抹眼泪,我还笑着安慰外婆说“别哭,这哭什么,我在国外也就待一年,很快就回来了”,外婆抹干了眼泪也笑着对我说“好,好,在外面注意安全”,现在才明白外婆当时就料到了自己可能挺不过这一年,不料那也真的成了我见外婆的最后一面,画面就这样永远的定格在了那一瞬,一个憨憨的小老太太坐在椅子上眼含泪水望着我和凤凤。
外婆总说我是她的骄傲,我也一定会更努力让她继续以我为傲,真心希望外婆在天国有一块温暖的地方,再无病痛和忧伤,唯有永远的阳光。
2014年6月19日星期四
2014年6月10日星期二
使用 CStdioFile 按行读入文件数据
CStdioFile 是 MFC 封装的 std::ifstream 和 std::ofstream 形成的一个类,可以按行从文件读入数据,使用起来非常的方便,详细使用说明参考 http://msdn.microsoft.com/en-us/library/a499td6y.aspx。
一个简单的读自定义点云文件(坐标、颜色及法向)的函数范例如下:
void ReadCloudFile(const CString & path, pcl::PointCloud<pcl::PointXYZRGB> & cloud, pcl::PointCloud<pcl::Normal> & normal)
{
cloud.clear();
normal.clear();
CStdioFile file;
if (!file.Open(path, CFile::modeRead))
{
return;
}
CString line;
while (file.ReadString(line))
{
if (line.IsEmpty())
{
continue;
}
double X,Y,Z,nX,nY,nZ;
int R,G,B;
sscanf(line, "%lf;%lf;%lf;%d;%d;%d;%lf;%lf;%lf", &X, &Y, &Z, &R, &G, &B, &nX, &nY, &nZ);
pcl::PointXYZRGB p;
pcl::Normal n;
p.x = X;
p.y = Y;
p.z = Z;
p.r = R;
p.g = G;
p.b = B;
n.normal_x = nX;
n.normal_y = nY;
n.normal_z = nZ;
cloud.push_back(p);
normal.push_back(n);
}
file.Close();
}
一个简单的读自定义点云文件(坐标、颜色及法向)的函数范例如下:
void ReadCloudFile(const CString & path, pcl::PointCloud<pcl::PointXYZRGB> & cloud, pcl::PointCloud<pcl::Normal> & normal)
{
cloud.clear();
normal.clear();
CStdioFile file;
if (!file.Open(path, CFile::modeRead))
{
return;
}
CString line;
while (file.ReadString(line))
{
if (line.IsEmpty())
{
continue;
}
double X,Y,Z,nX,nY,nZ;
int R,G,B;
sscanf(line, "%lf;%lf;%lf;%d;%d;%d;%lf;%lf;%lf", &X, &Y, &Z, &R, &G, &B, &nX, &nY, &nZ);
pcl::PointXYZRGB p;
pcl::Normal n;
p.x = X;
p.y = Y;
p.z = Z;
p.r = R;
p.g = G;
p.b = B;
n.normal_x = nX;
n.normal_y = nY;
n.normal_z = nZ;
cloud.push_back(p);
normal.push_back(n);
}
file.Close();
}
Conflict between window macro min max and std::min std::max
在新建一个新的 MFC 工程并单独添加 PCL 的时候,编译过程出现错误,提示 PCL 的相关文件中的 min 函数的输入参数个数不对,这其实是因为 windows 自己在 <window.h> 头中定义了宏 min 和 max 函数,而 PCL 中使用的 min 和 max 是 stl 中的函数,于是就产生了冲突,在网上找到一篇 microsoft 官方微博提供的关于此问题的一个解决方案:
http://support.microsoft.com/kb/143208
他的做法是在 Project->Properties->Configuration Properties->C/C++->Preprocessor->Preprocessor Definitions 中添加一个 NOMINMAX 的宏定义,这样的话 windows 自己的宏 min max 函数就不会被定义了,但是这样的做法是导致 MFC 中自己包含的很多确实用到该宏 min max 函数的地方报错,提示 min max 函数没定义,到此该问题的解决貌似成了一个鱼和熊掌不可兼得的情况。
回到 PCL 用户论坛继续找解决方案,最终找到一个方案,那就是在 stdafx.h 添加完所有 windows 自己头文件后,添加任何 PCL 头文件之前,通过 #undef 宏命令取消 windows 自己宏 min max 函数的定义:
#include "targetver.h"
#define _ATL_CSTRING_EXPLICIT_CONSTRUCTORS // some CString constructors will be explicit
// turns off MFC's hiding of some common and often safely ignored warning messages
#define _AFX_ALL_WARNINGS
#include <afxwin.h> // MFC core and standard components
#include <afxext.h> // MFC extensions
#include <afxdisp.h> // MFC Automation classes
#ifndef _AFX_NO_OLE_SUPPORT
#include <afxdtctl.h> // MFC support for Internet Explorer 4 Common Controls
#endif
#ifndef _AFX_NO_AFXCMN_SUPPORT
#include <afxcmn.h> // MFC support for Windows Common Controls
#endif // _AFX_NO_AFXCMN_SUPPORT
#include <afxcontrolbars.h> // MFC support for ribbons and control bars
#undef max
#undef min
#include <pcl/point_types.h>
#include <pcl/io/io.h>
这样的话所有的 windows 头还是用自己定义的 min max 函数,而所有 pcl 的库就用的 stl 的 min max 函数,这样做是合理的,因为 pcl 中肯定不会用到 windows 定义的 min max 函数。
http://support.microsoft.com/kb/143208
他的做法是在 Project->Properties->Configuration Properties->C/C++->Preprocessor->Preprocessor Definitions 中添加一个 NOMINMAX 的宏定义,这样的话 windows 自己的宏 min max 函数就不会被定义了,但是这样的做法是导致 MFC 中自己包含的很多确实用到该宏 min max 函数的地方报错,提示 min max 函数没定义,到此该问题的解决貌似成了一个鱼和熊掌不可兼得的情况。
回到 PCL 用户论坛继续找解决方案,最终找到一个方案,那就是在 stdafx.h 添加完所有 windows 自己头文件后,添加任何 PCL 头文件之前,通过 #undef 宏命令取消 windows 自己宏 min max 函数的定义:
#include "targetver.h"
#define _ATL_CSTRING_EXPLICIT_CONSTRUCTORS // some CString constructors will be explicit
// turns off MFC's hiding of some common and often safely ignored warning messages
#define _AFX_ALL_WARNINGS
#include <afxwin.h> // MFC core and standard components
#include <afxext.h> // MFC extensions
#include <afxdisp.h> // MFC Automation classes
#ifndef _AFX_NO_OLE_SUPPORT
#include <afxdtctl.h> // MFC support for Internet Explorer 4 Common Controls
#endif
#ifndef _AFX_NO_AFXCMN_SUPPORT
#include <afxcmn.h> // MFC support for Windows Common Controls
#endif // _AFX_NO_AFXCMN_SUPPORT
#include <afxcontrolbars.h> // MFC support for ribbons and control bars
#undef max
#undef min
#include <pcl/point_types.h>
#include <pcl/io/io.h>
这样的话所有的 windows 头还是用自己定义的 min max 函数,而所有 pcl 的库就用的 stl 的 min max 函数,这样做是合理的,因为 pcl 中肯定不会用到 windows 定义的 min max 函数。
2014年6月9日星期一
PCLVisualizer visualize my own point cloud and normals
经过一上午的代码整合与调试,终于可以通过 PCLVisualizer 来显示自己的点云和法向场了,效果如下:



需要注意的一点是在退出该三维显示窗口时最好是直接点叉关闭掉,如果是通过按 q 键来退出窗口的话,貌似显示内循环不会结束,就会导致内存泄露。
需要注意的一点是在退出该三维显示窗口时最好是直接点叉关闭掉,如果是通过按 q 键来退出窗口的话,貌似显示内循环不会结束,就会导致内存泄露。
error C2661: 'pcl::PointCloud::operator new' : no overloaded function takes 3 arguments
在 MFC 程序中使用如下语句时
pcl::PointCloud<pcl::PointXYZRGB>::Ptr cloud(new pcl::PointCloud<pcl::PointXYZRGB>);
pcl::PointCloud<pcl::Normal>::Ptr normal(new pcl::PointCloud<pcl::Normal>);
编译的时候会出现如下错误
error C2661: 'pcl::PointCloud<PointT>::operator new' : no overloaded function takes 3 arguments
google 一番发现这是因为 MFC wizard 为了跟踪内存分配在每个 MFC .cpp 中都加了以下三句话
#ifdef _DEBUG
#define new DEBUG_NEW
#endif
重新定义了 new,因此把每个 MFC .cpp 中的这三句屏蔽掉就可以编译通过了。
pcl::PointCloud<pcl::PointXYZRGB>::Ptr cloud(new pcl::PointCloud<pcl::PointXYZRGB>);
pcl::PointCloud<pcl::Normal>::Ptr normal(new pcl::PointCloud<pcl::Normal>);
编译的时候会出现如下错误
error C2661: 'pcl::PointCloud<PointT>::operator new' : no overloaded function takes 3 arguments
google 一番发现这是因为 MFC wizard 为了跟踪内存分配在每个 MFC .cpp 中都加了以下三句话
#ifdef _DEBUG
#define new DEBUG_NEW
#endif
重新定义了 new,因此把每个 MFC .cpp 中的这三句屏蔽掉就可以编译通过了。
error C3859: virtual memory range for PCH exceeded; please recompile with a command line option of '-Zm283' or greater
PCL confict with OpenCV : ‘flann’ : ambiguous symbol
昨天将 PCL 整合到大工程当中时,PCL 和 OpenCV 发生了冲突,PCL 中的第三方库 flann 和OpenCV 中的 cv::flann 产生了模糊,在 PCL 用户论坛还有 google 上找了一圈发现一个解决方案,就是将所有 PCL flann 库中的 flann:: 都改成 ::flann:: 编译就可以通过了,还不知道这是不是最优的解决方案。
另外我还是把 PCL 从 C 盘挪到了 D 盘,因为为了解决上面的问题需要修改 PCL 目录下的代码,在 C 盘由于权限无法完成修改,于是还是整体挪到了 D 盘,并相应的把环境变量路径改了过来。
2014年6月8日星期日
Installation of Point Cloud Library (PCL) and integration with Visual studio 2010 project
自从知道 Point Cloud Library (PCL) 之后就一直想用上它,尤其是其中的 point cloud visualization 模块以及 surface reconstruction 模块,可以更直观的呈现算法的结果。
首先到 http://pointclouds.org/downloads/windows.html 上面下载 PCL 1.6.0 All-In-One Installer,里面包含了 PCL 以及所有第三方库的头文件以及库文件等,下下来之后点击安装,在安装完成后选择为所有用户添加 PCL 路径。
完成安装后会发现此时系统已经自动将 PCL 的安装根目录 C:\Program Files\PCL 1.6.0 设为系统环境变量 PCL_ROOT,另外在默认索引 .dll 文件的 Path 系统变量中也已经添加了 C:\Program Files\PCL 1.6.0\bin 路径,避免了手动拷贝 .dll 到工程目录的必要。
接着在 VS2010 中新建了一个 win32 console 工程专门用来测试 PCL tutorials,并添加如下路径:
于 Project->Properties->Configuration Properties->C/C++->General->Additional Include Directories 中添加
$(PCL_ROOT)\include\pcl-1.6
$(PCL_ROOT)\3rdParty\Boost\include
$(PCL_ROOT)\3rdParty\Eigen\include
$(PCL_ROOT)\3rdParty\FLANN\include
$(PCL_ROOT)\3rdParty\Qhull\include
$(PCL_ROOT)\3rdParty\VTK\include\vtk-5.8
于 Project->Properties->Configuration Properties->Linker->General->Additional Library Directories 中添加
$(PCL_ROOT)\lib
$(PCL_ROOT)\3rdParty\Boost\lib
$(PCL_ROOT)\3rdParty\FLANN\lib
$(PCL_ROOT)\3rdParty\Qhull\lib
$(PCL_ROOT)\3rdParty\VTK\lib\vtk-5.8
最后要做的是把需要的 .lib 文件添加到
Project->Properties->Configuration Properties->Linker->Input->Additional Dependencies 中。
这里我没管哪些函数具体是包含在哪个 .lib 文件中,而是一股脑的把所有 debug 的 .lib 全部添加到了里面,省事,另外要强调的是 PCL 中所有可视函数不管是简单的 pcl::visualization::CloudViewer 还是功能强大的 pcl::visualization::PCLVisualizer 都是基于 VTK 显示库,所以要使用显示模块,VTK 的所有相关的 .lib 文件都得添加进来,最最需要注意的是 VTK 库函数中有很多是封装了 OpenGL 的基本函数,因此还得将 opengl32.lib 给添加进来,否则很多 VTK 函数会出现链接错误。
接着就准备开始测试,本来 PCL 安装好之后在其安装目录 $(PCL_ROOT)\share\doc\pcl-1.6\tutorials\sources 中有一个总的 CMakeLists 可以通过 CMake 2.8 make 出一个总的 PCLTutorial 工程来,其中包含了所有的 tutorials 工程,这里要注意的是,makefile 的时候输出路径尽量别选在 C:\ 中有权限限制的区域,可能无法 makefile,我最终是选择的输出在桌面。如此生成的工程虽然包含了所有的 tutorials 但是编译不能成功,提示需要 Qt 相关的 .lib 文件,即使单独运行某一个 tutorial 也不行,所以最终我还是选择了将单个感兴趣的 tutorial 代码粘贴到上面自己新建的 win32 console 工程来进行测试的方式。
其中 pcl_visualizer tutorial 运行的效果如下所示:


cloud_viewer tutorial 运行的效果如下所示:

总共有 46 万个点,在 debug 模式下显示的还是挺流畅的,感觉很不错,唯一不足的是响应鼠标拖动旋转的方式还是没有 CloudCompare 用着舒服。
最后要注意的是 pcl_visualizer tutorial 中的 int main(int argc, char ** argv) 函数需要根据用户输入的 argv 参数中的内容来进行不同模式的显示,这个参数是在调用 main 函数时输入的,做法就是通过命令提示符进入到 .exe 所在目录,然后通过如下格式输入不同参数来调用 main 函数:

首先到 http://pointclouds.org/downloads/windows.html 上面下载 PCL 1.6.0 All-In-One Installer,里面包含了 PCL 以及所有第三方库的头文件以及库文件等,下下来之后点击安装,在安装完成后选择为所有用户添加 PCL 路径。
完成安装后会发现此时系统已经自动将 PCL 的安装根目录 C:\Program Files\PCL 1.6.0 设为系统环境变量 PCL_ROOT,另外在默认索引 .dll 文件的 Path 系统变量中也已经添加了 C:\Program Files\PCL 1.6.0\bin 路径,避免了手动拷贝 .dll 到工程目录的必要。
接着在 VS2010 中新建了一个 win32 console 工程专门用来测试 PCL tutorials,并添加如下路径:
于 Project->Properties->Configuration Properties->C/C++->General->Additional Include Directories 中添加
$(PCL_ROOT)\include\pcl-1.6
$(PCL_ROOT)\3rdParty\Boost\include
$(PCL_ROOT)\3rdParty\Eigen\include
$(PCL_ROOT)\3rdParty\FLANN\include
$(PCL_ROOT)\3rdParty\Qhull\include
$(PCL_ROOT)\3rdParty\VTK\include\vtk-5.8
于 Project->Properties->Configuration Properties->Linker->General->Additional Library Directories 中添加
$(PCL_ROOT)\lib
$(PCL_ROOT)\3rdParty\Boost\lib
$(PCL_ROOT)\3rdParty\FLANN\lib
$(PCL_ROOT)\3rdParty\Qhull\lib
$(PCL_ROOT)\3rdParty\VTK\lib\vtk-5.8
最后要做的是把需要的 .lib 文件添加到
Project->Properties->Configuration Properties->Linker->Input->Additional Dependencies 中。
这里我没管哪些函数具体是包含在哪个 .lib 文件中,而是一股脑的把所有 debug 的 .lib 全部添加到了里面,省事,另外要强调的是 PCL 中所有可视函数不管是简单的 pcl::visualization::CloudViewer 还是功能强大的 pcl::visualization::PCLVisualizer 都是基于 VTK 显示库,所以要使用显示模块,VTK 的所有相关的 .lib 文件都得添加进来,最最需要注意的是 VTK 库函数中有很多是封装了 OpenGL 的基本函数,因此还得将 opengl32.lib 给添加进来,否则很多 VTK 函数会出现链接错误。
接着就准备开始测试,本来 PCL 安装好之后在其安装目录 $(PCL_ROOT)\share\doc\pcl-1.6\tutorials\sources 中有一个总的 CMakeLists 可以通过 CMake 2.8 make 出一个总的 PCLTutorial 工程来,其中包含了所有的 tutorials 工程,这里要注意的是,makefile 的时候输出路径尽量别选在 C:\ 中有权限限制的区域,可能无法 makefile,我最终是选择的输出在桌面。如此生成的工程虽然包含了所有的 tutorials 但是编译不能成功,提示需要 Qt 相关的 .lib 文件,即使单独运行某一个 tutorial 也不行,所以最终我还是选择了将单个感兴趣的 tutorial 代码粘贴到上面自己新建的 win32 console 工程来进行测试的方式。
其中 pcl_visualizer tutorial 运行的效果如下所示:
cloud_viewer tutorial 运行的效果如下所示:
总共有 46 万个点,在 debug 模式下显示的还是挺流畅的,感觉很不错,唯一不足的是响应鼠标拖动旋转的方式还是没有 CloudCompare 用着舒服。
最后要注意的是 pcl_visualizer tutorial 中的 int main(int argc, char ** argv) 函数需要根据用户输入的 argv 参数中的内容来进行不同模式的显示,这个参数是在调用 main 函数时输入的,做法就是通过命令提示符进入到 .exe 所在目录,然后通过如下格式输入不同参数来调用 main 函数:
留学期间阅读的文献汇总,三季度
1. Fast Range Image Segmentation and Smoothing Using Approximate Surface Reconstruction and Region Growing (completely read on 7th Jun 2014).
这是德国 University of Bonn 的 Dirk Holz 和 Sven Behnke 在 2013 年第 12 届 intelligent autonomous systems 大会上发表的一篇文章。
我其实是在 Point Cloud Library (PCL) 的 Surface extraction 模块的文档介绍中看到该文章的,因为 PCL 的 surface 模块里有一个函数 pcl::OrganizedFastMesh< PointInT > 就是实现的该文的算法。
正如本文题目中申明的那样,其最主要的目的是对深度图进行分割和平滑,我看本文主要的目的是看他里面如何对 organized point cloud (e.g. range image) 进行快速 mesh。文章的第 2 大节中把 range image segmentation 方法分为 3 大类:RANSAC, 3D Hough transform and region growing,作为了解。
直奔我最关心的 fast approximate meshing,其实我认为文中关于这部分的描述有问题,每次少考虑了邻域中的一个像素,关于我自己对 fast approximate meshing 的理解在笔记本里有详细叙述。然后关于其算法中如何快速求 mesh 中每个 vertex 的法向,以及后续如何对每个 vertex 的位置及其法向利用其与邻域 vertices 之间位置、法向以及颜色的邻近程度来进行 bilateral filtering 也一概在笔记本中有详细描述。
2. Occluding Contours for Multi-View Stereo (completely read on 8th Jun 2014).
本文是 Qi Shan, B. Curless, Y. Furukawa 以及 S. M. Seitz 在 2014 年的一篇文章。
3. Accurate Multiple View 3D Reconstruction Using Patch-Based Stereo for Large-Scale Scenes (completely read on 16th Jun 2014).
这篇文章是 SWJTU 的一位校友 Shuhan Shen 于 2013 年发表在 IEEE TRANSACTIONS ON IMAGE PROCESSING 上一篇文章,该校友 06 年于 SWJTU 毕业,之后于 10 年又拿到了 SJTU 的博士学位,现就职于北京中科院模式识别自动化所。
这篇文章的思路对于我来说还是很清晰的,该算法也是输入一堆图像,然后输出是为每个输入图像生成了一幅深度图,他的算法主要分成以下 4 步骤:
一、Stereo Pair Selection. 首先为每一幅图像选择一幅支持图像,文中将支持图像称为 reference image,whatever,选择的准则就是两幅图之间要有相似的视线角,以及不能太宽(重合区域少)也不能太窄(重建精度低)的基线,具体方法参考原文,总之其同时考虑了视线夹角以及基线长度;
二、Depth-Map Computation. 这一部分是该文最核心的部分,与当前我的方法中采用深度梯度来表示表面法向的方式不同,该文中采用的是真正的空间平面解析表达式的形式,当时我认为要解析的表示出该空间平面需要多于两个自由度的参数,但是却从未想过可以把平面放到像机坐标系下用两个球体极坐标来表示,这样平面法向参数表示也就是两个自由度了。有了空间平面的解析表示后,就可以通过空间平面诱导出两图像间的单应了,匹配像点之间的转移也更为简单(左乘诱导单应)。其后的过程我已经很熟悉了;
三、Depth-Map Refinement. 这一部分其实就是利用我的方法中 depth consistency check 来剔除 outliers;
四、Depth-Map Merging. 这一步中作者要做的是把匹配的很多冗余量给剔除掉,但实际上这样做损失了精度,没有将冗余观测利用起来提高重建精度。
4. Quasi-Dense 3D Reconstruction using Tensor-Based Multiview Stereo (completely read on 18th Jun 2014).
这篇文章是香港科技大学 (HKUST) Tai-Pang Wu 2010 年的一篇 CVPR 文章,文献【3】的 Introduction 中有介绍该文章,所以就下下来看了。
该文方法基于 PMVS 的主体框架,在其各个环节中引入 Tensor Voting 机制以优化得到更准的法向估计和坐标,以及更好的剔除 outliers。
关于 Tensor voting 可以参考 T. P. Wu 2012 年的 TPAMI 文章。
该文方法主要将 Tensor voting 用到了 PMVS 的一下 3 个环节:
一、Match. 也就是 PMVS 中对 features 进行稀疏重建的环节,这个环节中 tensor voting 的介入有两种情况,一种是当图像未标定的时候,也就是内定向及外定向未知时,这时候一般的做法是进行 SfM 通过 RANSAC 来先估计两视图间的基础矩阵同时进行特征匹配,而本文提出一种基于 Expectation-Maximization 参数估计方法的 EMTV 算法可以用来同时估计基础矩阵和进行匹配,是类似于 RANSAC 的一种鲁棒方法,据文中给出的结果 EMTV 方法得到了更好的稀疏重建结果;另一种情形就是当图像完成了标定的时候,这时候 TV 可以用来优化稀疏重建的 patches 的法向,做法就是每个 patch 都收集其邻近的 patches 的张量,得到其更新的张量,并从中得到新法向,以下是经过 TV 前后的法向重建结果对比;

二、Propagation. PMVS 原文中的做法是根据已经存在的 patches 的法向和邻域先生成一系列候选的三维点位,然后沿每个候选点的视线方向去优化该候选点的法向和位置。本文方法也将 TV 应用在了这一环节中,具体点就是应用在了候选点法向和位置的优化上,它是怎么去优化的呢,首先也是沿着候选点的视线方向去调整采样,并记录每个采样位置处的 photoconsistency (NCC) 程度和 surface saliency 程度(邻域内对该采样位置处的 TV),并定义了如下的一个同时考虑了photoconsistency 和 surface saliency 的综合指标,并最终选择拥有最优该指标的采样位置和得到的法向作为最终优化值;

三、Filtering. 这一步里面作者用其所谓的 MRF-TV 来进一步剔除 outliers,详见原文。
5. A Closed-Form Solution to Tensor Voting: Theory and Applications (completely read on 19th Jun 2014).
上文作者 Tai-Pang Wu 于 2010 年发表在 TPAMI 上的一篇详细介绍其 CFTV 原理的文章,里面有一些思路很巧妙的地方,尤其是给定一个位置上的法向,如何推断指定点位上的最有可能的法向,其实 Tensor voting 的思想最早是由 University of South California 的 Gerard G. Medioni 教授提出来的,只不过在 CFTV 之前的 TV 应用都是先要计算一些 precomputed tensor fields,也就是说是数值的形式,而这里 CFTV 是闭合的解析的形式,计算点 j 处张量 Kj 在点 i 处的投票直接使用如下式子,而无需再事先计算 precomputed voting fields 了,其实关于其中的积分公式我有详细的笔记和解读。

6. Combined Depth and Outlier Estimation in Multi-View Stereo (completely read on 24th Jun 2014).
C. Strecha 2006 年的一篇 CVPR,很早之前就尝试着看过一两次,但都没有看太明白,主要是对其中采用的 Expectation-Maximizaiton 思想不太明白,但是最近自学了参数估计里的 MLE, MAP, Bayesian Estimator 和 EM 算法之后,现在终于算是明白这篇文章的方法了,该文中的方法思路还是非常有创造性的,详细的理解和解读在笔记当中有。
7. PM-Huber: PatchMatch with Huber Regularization for Stereo Matching (completely read on 29th Jun 2014).
这是慕尼黑工业大学的 P. Heise 在 2013 年发表的一篇 ICCV 文章,文章的方法还是 Binocular stereo 方法,需要对两视图进行图像矫正,考虑的还是视差,另外其采用的 support window model 依然是 M. Bleyer 2011 年文章中的模型,即 disparity space plane model,只不过本文中对 window 中像素在两视图中的转移公式用单应解析的表示出来了。
可以这么说吧,本文并不是我一开始设想的是在原 PatchMatch 的框架中加入了 smoothness 项,然后最终结果可以达到能量函数全局最优的这么一种方式,本文的方法实际上应该是早就有了一个分步交替求解全局最优的框架,只不过其中的一步原本涉及到 brutal force searching 本文就想到了用 PatchMatch 来代替原来的 brutal force searching 提高计算速度。
本文最核心的思路就是借鉴了 Frank Steinbrucker 2009 年在 ICCV 的文章 Large Displacement Optical Flow Computation without Warping 中的思路,就是把传统的能量函数通过使用 Quadratic relaxation,即添加一个 auxiliary parameter field 构成一个 quadratic term 将之前的耦合在一起的 data term 和 smoothness term 解耦成两个独立的优化问题,如下式所示。

其中 u 和 v 是两个参数场,每个像素都包含了视差和法向参数,已知并固定 u 场时求解上面式子关于 v 场的最小化问题是一个 convex 的问题,可以通过传统的非线性优化方法来求解得到;然后已知并固定 v 场,求解上面式子关于 u 场的最小化问题就变成只跟 u 有关的问题,没有平滑项了,这时求解上式关于 u 场的最优化问题就用到了 PatchMatch 的思路,而不是 F. Steinbrucker 原文中的 brutal force 的方式,来寻求此时最优的 u 场;就这样求 u 场和求 v 场的两个各自全局最优化过程交替进行,并且每轮迭代后增加 sita 的值,当 sita 趋向于无穷时,上式的能量函数就和传统的能量函数一致了,而两个参数场 u 和 v 也趋向于相等了。
我得说这篇文章虽然直到现在才看懂,但是其思路真的非常不错,通过 Quadratic relaxation 完成 data term 和 smoothness term 的解耦,将能量函数全局最优问题拆成两个独立的优化问题,并交替进行直到收敛,真是不错。
8. Large Displacement Optical Flow Computation without Warping (completely read on 29th Jun 2014).
这篇文章就是文献【7】中借鉴的思路的出处,原文中其实是用 quadratic relaxation 来解耦一个 optical flow estimation 的能量全局最优问题,然后现在就被文献【7】用到了 Binocular stereo 当中,我相信这只是一个开始。
9. Real-Time Visibility-Based Fusion of Depth Maps (completely read on 7th Jul 2014).
Paul Merrell 在 2007 年的一篇 ICCV 文章,总的来说这篇文章看起来很费力,其中很多标示符和名词都有出现前后意思矛盾的情况,条理也不够清晰,看起来特别的费劲。
文章提出的算法是一种 multi-view stereo 算法,输入一堆图像,为每一幅图像选择 4-10 幅支持图集,并以此估计相对于参考图的深度图,其估计深度的方法主要是所谓的 plane-sweeping 方法,虽然不清楚具体做法,但可以肯定的是它是对深度有离散的,并且遍历了所有离散深度,并最终选取匹配代价最小的深度,而且可以肯定是每个像素处所有离散深度处的匹配代价是有内存记录的,因为文中要基于下式利用所有的匹配代价来计算选取深度的置信程度。也就是说每个深度图中的每个深度值都有对应的置信度。该置信度表征了对应深度值的单峰程度,要是单峰程度高的话说明该深度为最优的可能性越大。

在有了所有的深度图和置信度图之后,就开始进行其所谓的 visibility-based depth map fusion 了,文中提出的 fusion 方法有两种,一种是 stability-based fusion,一种是 confidence-based fusion。如左下图所示,文中将两个深度图之间可能存在的关系概括为三种,一种是 free-space violation,如图中 A 和 A' 的情况,一种是如 B=B' 所示深度相符合,另一种是如 C 和 C' 的情况,即 occlusion。

文中虽然声明了其 stability-based fusion 并不是简单的中值滤波,但我看完之后其实就是中值滤波,他将所有支持图集的深度图 render 到参考图中,然后选择所谓的 closest stable depth 作为最终的深度,按照 stable 的定义可以认为绝大多数情况下其最终选的深度就是中值深度,只不过他这里要把 free-space violation 和 occlusion 的概念给用上。
然后文中的 confidence-based fusion 可以认为就是利用了 confidence 加权的一个深度加权均值。
10. Scale Robust Multi View Stereo (completely read on 8th Jul 2014).
Christian Bailer 2012 发表的一篇 ECCV 文章,本文算法的一个重要特点就是可以 handle huge unstructured image datasets,也就是说可以同时利用不同空间分辨率(或者图像采样率抑或是尺度)的图像来进行 MVS,其算法的各个环节都有考虑利用到了图像尺度的信息,不仅仅是在一开始选择支持图集的过程中,还有后续深度融合的过程中。
首先,文中算法的总体流程是标准的 MVS 流程,即首先为每一幅输入图像通过一定机制选择多幅合适的支持图像组成支持图集,然后利用该支持图集通过核心的 MVS 算法生成相对于该参考图的深度图,重复该过程为每一幅输入图像生成深度图,之后再利用已有的初始的各深度图进行相互比较来去除 outliers 和进一步优化。
一、Image Selection. 文中选择支持图集是要基于稀疏特征匹配的结果,详细算法见文章,总之其选择算法要达成的效果就是使得支持图集与参考图之间的视线夹角较 Goesele 的方法更大,但又不会造成尺度差异太大;
二、Depth Map Creation. 其深度图生成的过程采用的是 PatchMatch 的机制,最有意思的一点是其综合 NCC 评分定义,如下所示,是一种 self-weighted score,可以自适应的抑制小 NCC 值对最终综合评分的影响,即文中所称的 occlusion robust and performed even at non-occluded surface parts better than a common weighting。

由于文中采用了上述的 self-weighted score,因此其在考察综合评分时,没有按照一定的 NCC 阈值来完全屏蔽低 NCC 值对深度评价的影响,因为作者认为用上述综合评分已经可以自适应的抑制低 NCC 值(即可能的 occlusion)的影响了,因此考察某深度值时,总是用的所有支持图像来进行的匹配,之后为了剔除仍然可能存在的误匹配,文中算法首先把那些存在误匹配(即 NCC 低于一定值)个数超过一定阈值的深度给剔除掉,然后还利用深度连接性对深度图进行分割聚类,将那些少于 15 个深度点的区域当作 outliers 给剔除掉。
三、Multi Depth Map Filtering. 这一步就是利用上面为每一个图像生成的深度图来进一步剔除 outliers,他这里的 filtering 利用到了上一篇文献中提到的 free-space violation 和 occlusion 的概念,连图都搬过来了,只不过他这里只用这些概念来剔除 depth values 即 filtering,不是用来做 depth fusion 或者优化。这一步里面剔除那些下式值小于 1 的 depth values,其中 rb 常数文中定义为 2。
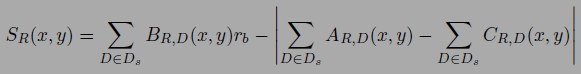
四、 Point Selection and Optimization. 这一步里面文中利用每个深度图的焦距和深度值为每个深度值对应的空间点分配了一个作用半径以及尺度值,就相当于误差椭球吧,然后先是选择那些作用半径里没有更小作用半径的空间点为所谓 primary point,并声明这些 primary points 代表了它附近拥有最优分辨率的点,因此也最有可能是精度最高的空间点,然后文章再利用每个 primary point 邻域内相同尺度的点来沿其法向迭代优化其位置及法向,详细过程见原文。
五、Meshing. 这一步里面文中采用到了 Delaunay Graph Cut 来做 meshing,原文为 Robust and efficient surface reconstruction from range data,值得看一下。
这是德国 University of Bonn 的 Dirk Holz 和 Sven Behnke 在 2013 年第 12 届 intelligent autonomous systems 大会上发表的一篇文章。
我其实是在 Point Cloud Library (PCL) 的 Surface extraction 模块的文档介绍中看到该文章的,因为 PCL 的 surface 模块里有一个函数 pcl::OrganizedFastMesh< PointInT > 就是实现的该文的算法。
正如本文题目中申明的那样,其最主要的目的是对深度图进行分割和平滑,我看本文主要的目的是看他里面如何对 organized point cloud (e.g. range image) 进行快速 mesh。文章的第 2 大节中把 range image segmentation 方法分为 3 大类:RANSAC, 3D Hough transform and region growing,作为了解。
直奔我最关心的 fast approximate meshing,其实我认为文中关于这部分的描述有问题,每次少考虑了邻域中的一个像素,关于我自己对 fast approximate meshing 的理解在笔记本里有详细叙述。然后关于其算法中如何快速求 mesh 中每个 vertex 的法向,以及后续如何对每个 vertex 的位置及其法向利用其与邻域 vertices 之间位置、法向以及颜色的邻近程度来进行 bilateral filtering 也一概在笔记本中有详细描述。
2. Occluding Contours for Multi-View Stereo (completely read on 8th Jun 2014).
本文是 Qi Shan, B. Curless, Y. Furukawa 以及 S. M. Seitz 在 2014 年的一篇文章。
3. Accurate Multiple View 3D Reconstruction Using Patch-Based Stereo for Large-Scale Scenes (completely read on 16th Jun 2014).
这篇文章是 SWJTU 的一位校友 Shuhan Shen 于 2013 年发表在 IEEE TRANSACTIONS ON IMAGE PROCESSING 上一篇文章,该校友 06 年于 SWJTU 毕业,之后于 10 年又拿到了 SJTU 的博士学位,现就职于北京中科院模式识别自动化所。
这篇文章的思路对于我来说还是很清晰的,该算法也是输入一堆图像,然后输出是为每个输入图像生成了一幅深度图,他的算法主要分成以下 4 步骤:
一、Stereo Pair Selection. 首先为每一幅图像选择一幅支持图像,文中将支持图像称为 reference image,whatever,选择的准则就是两幅图之间要有相似的视线角,以及不能太宽(重合区域少)也不能太窄(重建精度低)的基线,具体方法参考原文,总之其同时考虑了视线夹角以及基线长度;
二、Depth-Map Computation. 这一部分是该文最核心的部分,与当前我的方法中采用深度梯度来表示表面法向的方式不同,该文中采用的是真正的空间平面解析表达式的形式,当时我认为要解析的表示出该空间平面需要多于两个自由度的参数,但是却从未想过可以把平面放到像机坐标系下用两个球体极坐标来表示,这样平面法向参数表示也就是两个自由度了。有了空间平面的解析表示后,就可以通过空间平面诱导出两图像间的单应了,匹配像点之间的转移也更为简单(左乘诱导单应)。其后的过程我已经很熟悉了;
三、Depth-Map Refinement. 这一部分其实就是利用我的方法中 depth consistency check 来剔除 outliers;
四、Depth-Map Merging. 这一步中作者要做的是把匹配的很多冗余量给剔除掉,但实际上这样做损失了精度,没有将冗余观测利用起来提高重建精度。
4. Quasi-Dense 3D Reconstruction using Tensor-Based Multiview Stereo (completely read on 18th Jun 2014).
这篇文章是香港科技大学 (HKUST) Tai-Pang Wu 2010 年的一篇 CVPR 文章,文献【3】的 Introduction 中有介绍该文章,所以就下下来看了。
该文方法基于 PMVS 的主体框架,在其各个环节中引入 Tensor Voting 机制以优化得到更准的法向估计和坐标,以及更好的剔除 outliers。
关于 Tensor voting 可以参考 T. P. Wu 2012 年的 TPAMI 文章。
该文方法主要将 Tensor voting 用到了 PMVS 的一下 3 个环节:
一、Match. 也就是 PMVS 中对 features 进行稀疏重建的环节,这个环节中 tensor voting 的介入有两种情况,一种是当图像未标定的时候,也就是内定向及外定向未知时,这时候一般的做法是进行 SfM 通过 RANSAC 来先估计两视图间的基础矩阵同时进行特征匹配,而本文提出一种基于 Expectation-Maximization 参数估计方法的 EMTV 算法可以用来同时估计基础矩阵和进行匹配,是类似于 RANSAC 的一种鲁棒方法,据文中给出的结果 EMTV 方法得到了更好的稀疏重建结果;另一种情形就是当图像完成了标定的时候,这时候 TV 可以用来优化稀疏重建的 patches 的法向,做法就是每个 patch 都收集其邻近的 patches 的张量,得到其更新的张量,并从中得到新法向,以下是经过 TV 前后的法向重建结果对比;
二、Propagation. PMVS 原文中的做法是根据已经存在的 patches 的法向和邻域先生成一系列候选的三维点位,然后沿每个候选点的视线方向去优化该候选点的法向和位置。本文方法也将 TV 应用在了这一环节中,具体点就是应用在了候选点法向和位置的优化上,它是怎么去优化的呢,首先也是沿着候选点的视线方向去调整采样,并记录每个采样位置处的 photoconsistency (NCC) 程度和 surface saliency 程度(邻域内对该采样位置处的 TV),并定义了如下的一个同时考虑了photoconsistency 和 surface saliency 的综合指标,并最终选择拥有最优该指标的采样位置和得到的法向作为最终优化值;
三、Filtering. 这一步里面作者用其所谓的 MRF-TV 来进一步剔除 outliers,详见原文。
5. A Closed-Form Solution to Tensor Voting: Theory and Applications (completely read on 19th Jun 2014).
上文作者 Tai-Pang Wu 于 2010 年发表在 TPAMI 上的一篇详细介绍其 CFTV 原理的文章,里面有一些思路很巧妙的地方,尤其是给定一个位置上的法向,如何推断指定点位上的最有可能的法向,其实 Tensor voting 的思想最早是由 University of South California 的 Gerard G. Medioni 教授提出来的,只不过在 CFTV 之前的 TV 应用都是先要计算一些 precomputed tensor fields,也就是说是数值的形式,而这里 CFTV 是闭合的解析的形式,计算点 j 处张量 Kj 在点 i 处的投票直接使用如下式子,而无需再事先计算 precomputed voting fields 了,其实关于其中的积分公式我有详细的笔记和解读。
6. Combined Depth and Outlier Estimation in Multi-View Stereo (completely read on 24th Jun 2014).
C. Strecha 2006 年的一篇 CVPR,很早之前就尝试着看过一两次,但都没有看太明白,主要是对其中采用的 Expectation-Maximizaiton 思想不太明白,但是最近自学了参数估计里的 MLE, MAP, Bayesian Estimator 和 EM 算法之后,现在终于算是明白这篇文章的方法了,该文中的方法思路还是非常有创造性的,详细的理解和解读在笔记当中有。
7. PM-Huber: PatchMatch with Huber Regularization for Stereo Matching (completely read on 29th Jun 2014).
这是慕尼黑工业大学的 P. Heise 在 2013 年发表的一篇 ICCV 文章,文章的方法还是 Binocular stereo 方法,需要对两视图进行图像矫正,考虑的还是视差,另外其采用的 support window model 依然是 M. Bleyer 2011 年文章中的模型,即 disparity space plane model,只不过本文中对 window 中像素在两视图中的转移公式用单应解析的表示出来了。
可以这么说吧,本文并不是我一开始设想的是在原 PatchMatch 的框架中加入了 smoothness 项,然后最终结果可以达到能量函数全局最优的这么一种方式,本文的方法实际上应该是早就有了一个分步交替求解全局最优的框架,只不过其中的一步原本涉及到 brutal force searching 本文就想到了用 PatchMatch 来代替原来的 brutal force searching 提高计算速度。
本文最核心的思路就是借鉴了 Frank Steinbrucker 2009 年在 ICCV 的文章 Large Displacement Optical Flow Computation without Warping 中的思路,就是把传统的能量函数通过使用 Quadratic relaxation,即添加一个 auxiliary parameter field 构成一个 quadratic term 将之前的耦合在一起的 data term 和 smoothness term 解耦成两个独立的优化问题,如下式所示。
其中 u 和 v 是两个参数场,每个像素都包含了视差和法向参数,已知并固定 u 场时求解上面式子关于 v 场的最小化问题是一个 convex 的问题,可以通过传统的非线性优化方法来求解得到;然后已知并固定 v 场,求解上面式子关于 u 场的最小化问题就变成只跟 u 有关的问题,没有平滑项了,这时求解上式关于 u 场的最优化问题就用到了 PatchMatch 的思路,而不是 F. Steinbrucker 原文中的 brutal force 的方式,来寻求此时最优的 u 场;就这样求 u 场和求 v 场的两个各自全局最优化过程交替进行,并且每轮迭代后增加 sita 的值,当 sita 趋向于无穷时,上式的能量函数就和传统的能量函数一致了,而两个参数场 u 和 v 也趋向于相等了。
我得说这篇文章虽然直到现在才看懂,但是其思路真的非常不错,通过 Quadratic relaxation 完成 data term 和 smoothness term 的解耦,将能量函数全局最优问题拆成两个独立的优化问题,并交替进行直到收敛,真是不错。
8. Large Displacement Optical Flow Computation without Warping (completely read on 29th Jun 2014).
这篇文章就是文献【7】中借鉴的思路的出处,原文中其实是用 quadratic relaxation 来解耦一个 optical flow estimation 的能量全局最优问题,然后现在就被文献【7】用到了 Binocular stereo 当中,我相信这只是一个开始。
9. Real-Time Visibility-Based Fusion of Depth Maps (completely read on 7th Jul 2014).
Paul Merrell 在 2007 年的一篇 ICCV 文章,总的来说这篇文章看起来很费力,其中很多标示符和名词都有出现前后意思矛盾的情况,条理也不够清晰,看起来特别的费劲。
文章提出的算法是一种 multi-view stereo 算法,输入一堆图像,为每一幅图像选择 4-10 幅支持图集,并以此估计相对于参考图的深度图,其估计深度的方法主要是所谓的 plane-sweeping 方法,虽然不清楚具体做法,但可以肯定的是它是对深度有离散的,并且遍历了所有离散深度,并最终选取匹配代价最小的深度,而且可以肯定是每个像素处所有离散深度处的匹配代价是有内存记录的,因为文中要基于下式利用所有的匹配代价来计算选取深度的置信程度。也就是说每个深度图中的每个深度值都有对应的置信度。该置信度表征了对应深度值的单峰程度,要是单峰程度高的话说明该深度为最优的可能性越大。
在有了所有的深度图和置信度图之后,就开始进行其所谓的 visibility-based depth map fusion 了,文中提出的 fusion 方法有两种,一种是 stability-based fusion,一种是 confidence-based fusion。如左下图所示,文中将两个深度图之间可能存在的关系概括为三种,一种是 free-space violation,如图中 A 和 A' 的情况,一种是如 B=B' 所示深度相符合,另一种是如 C 和 C' 的情况,即 occlusion。
文中虽然声明了其 stability-based fusion 并不是简单的中值滤波,但我看完之后其实就是中值滤波,他将所有支持图集的深度图 render 到参考图中,然后选择所谓的 closest stable depth 作为最终的深度,按照 stable 的定义可以认为绝大多数情况下其最终选的深度就是中值深度,只不过他这里要把 free-space violation 和 occlusion 的概念给用上。
然后文中的 confidence-based fusion 可以认为就是利用了 confidence 加权的一个深度加权均值。
10. Scale Robust Multi View Stereo (completely read on 8th Jul 2014).
Christian Bailer 2012 发表的一篇 ECCV 文章,本文算法的一个重要特点就是可以 handle huge unstructured image datasets,也就是说可以同时利用不同空间分辨率(或者图像采样率抑或是尺度)的图像来进行 MVS,其算法的各个环节都有考虑利用到了图像尺度的信息,不仅仅是在一开始选择支持图集的过程中,还有后续深度融合的过程中。
首先,文中算法的总体流程是标准的 MVS 流程,即首先为每一幅输入图像通过一定机制选择多幅合适的支持图像组成支持图集,然后利用该支持图集通过核心的 MVS 算法生成相对于该参考图的深度图,重复该过程为每一幅输入图像生成深度图,之后再利用已有的初始的各深度图进行相互比较来去除 outliers 和进一步优化。
一、Image Selection. 文中选择支持图集是要基于稀疏特征匹配的结果,详细算法见文章,总之其选择算法要达成的效果就是使得支持图集与参考图之间的视线夹角较 Goesele 的方法更大,但又不会造成尺度差异太大;
二、Depth Map Creation. 其深度图生成的过程采用的是 PatchMatch 的机制,最有意思的一点是其综合 NCC 评分定义,如下所示,是一种 self-weighted score,可以自适应的抑制小 NCC 值对最终综合评分的影响,即文中所称的 occlusion robust and performed even at non-occluded surface parts better than a common weighting。
由于文中采用了上述的 self-weighted score,因此其在考察综合评分时,没有按照一定的 NCC 阈值来完全屏蔽低 NCC 值对深度评价的影响,因为作者认为用上述综合评分已经可以自适应的抑制低 NCC 值(即可能的 occlusion)的影响了,因此考察某深度值时,总是用的所有支持图像来进行的匹配,之后为了剔除仍然可能存在的误匹配,文中算法首先把那些存在误匹配(即 NCC 低于一定值)个数超过一定阈值的深度给剔除掉,然后还利用深度连接性对深度图进行分割聚类,将那些少于 15 个深度点的区域当作 outliers 给剔除掉。
三、Multi Depth Map Filtering. 这一步就是利用上面为每一个图像生成的深度图来进一步剔除 outliers,他这里的 filtering 利用到了上一篇文献中提到的 free-space violation 和 occlusion 的概念,连图都搬过来了,只不过他这里只用这些概念来剔除 depth values 即 filtering,不是用来做 depth fusion 或者优化。这一步里面剔除那些下式值小于 1 的 depth values,其中 rb 常数文中定义为 2。
四、 Point Selection and Optimization. 这一步里面文中利用每个深度图的焦距和深度值为每个深度值对应的空间点分配了一个作用半径以及尺度值,就相当于误差椭球吧,然后先是选择那些作用半径里没有更小作用半径的空间点为所谓 primary point,并声明这些 primary points 代表了它附近拥有最优分辨率的点,因此也最有可能是精度最高的空间点,然后文章再利用每个 primary point 邻域内相同尺度的点来沿其法向迭代优化其位置及法向,详细过程见原文。
五、Meshing. 这一步里面文中采用到了 Delaunay Graph Cut 来做 meshing,原文为 Robust and efficient surface reconstruction from range data,值得看一下。
2014年5月24日星期六
Food on Lygon Street
我的办公室就位于 Melbourne 著名的意大利街 Lygon St 上,Lygon St 两旁充斥着大量的意大利美食店,到目前为止我去过两家,第一次去的那家名字忘了,好像是什么 Pizza restaurant,吃的是正宗的意大利披萨,见下图。



今天中午和宇翔好不容易找到车位停好车以后没着急来办公室,而是在对面的 Coco Black 一人点了一杯 hot chocolate 喝上了,味道和口感都是极好的,上面的花纹做的也很精致好看,价格呢稍贵 6.5 刀,但我认为这样的品质绝对也值这个价了,为了对抗午间强大的困意,估计以后会常来 Coco Black 了。

点的是 median size,分量很足,味道也绝非国内的必胜客里的披萨所能比的,确实赞。
第二次去的是 Papa Gino,名字朗朗上口,很好记,这家店生意超火,店门外常常看到排起很长的队,在 papa gino 吃的是 pasta,本以为是空心粉的样式,端上来才发现是另一种 pasta,有点像饺子,见下图,papa gino 的价格也更亲民一些,分量同样很足。
今天中午和宇翔好不容易找到车位停好车以后没着急来办公室,而是在对面的 Coco Black 一人点了一杯 hot chocolate 喝上了,味道和口感都是极好的,上面的花纹做的也很精致好看,价格呢稍贵 6.5 刀,但我认为这样的品质绝对也值这个价了,为了对抗午间强大的困意,估计以后会常来 Coco Black 了。
2014年5月19日星期一
fscanf and uchar
昨晚企图运行程序,对代码稍加改动了一下,结果程序运行异常,别说主体代码运行不了,就连 opencv 的 imwrite 函数都用不了了,而且最恼火就是 debug 下正常,就 release 出问题,没法进行调试,上午一大早过来继续查错误,一直整到十点半还是不能确定原因,没法,只能是把新加代码完全删掉,然后增量式的添加代码,看到底是哪些新添加的代码导致了问题,后来确定了问题发生在下面第一句上,
fscanf(pfile, "%d ", &uchar);
mat.at<uchar>(i,j) = uchar;
后来改成
fscanf(pfile, "%d ", &int);
mat.at<uchar>(i,j) = (uchar)int;
问题就没有了,只是有点想不通为什么这里读取文件不对还会影响整个前后端程序的运行,imwrite 函数运行都会报错。
fscanf(pfile, "%d ", &uchar);
mat.at<uchar>(i,j) = uchar;
后来改成
fscanf(pfile, "%d ", &int);
mat.at<uchar>(i,j) = (uchar)int;
问题就没有了,只是有点想不通为什么这里读取文件不对还会影响整个前后端程序的运行,imwrite 函数运行都会报错。
2014年5月12日星期一
Implementation of Census Transform
花了一上午的时间把 Census Transform 用 C 给实现了一遍,目前实现的版本按照窗口大小的不同有 3 个版本,3×3,、5×5 以及 9×7 的版本,3×3 的版本最终生成的 bit string 长度为 8 个字位,正好为 1 个字节,可以用一个 opencv 定义的 uchar 类型来表示,5×5 版本的 bit string 则为 24 个字位,3 个字节,因此只能用 4 个字节的数据类型来表示,目前选用的是 MS 的 UINT,最后 9×7 版本的 bit string 为 62 个字位,得用 8 个字节的数据类型表示,一开始理所当然的以为可以选用 double 类型,因为 double 正好 8 个字节,但是由于生成 census transform bit string 的过程中要用到移位的操作,而移位操作只能在整型数据类型上进行,因此最后选用了 opencv 定义的 uint64 类型。下面附上计算 5×5 窗口 census transform bit string 的函数:

两个 census transform bit string 之间的相似性是通过 Hamming distance 来表征的,计算 hamming distance 的 C 实现在 wikipedia 上面就有,http://en.wikipedia.org/wiki/Hamming_distance,是 Wegner 1960 年提出的方法,其运算量和最终的 hamming distance 大小成比例,而不是和 bit string 的长度成比例,函数如下:

两个 census transform bit string 之间的相似性是通过 Hamming distance 来表征的,计算 hamming distance 的 C 实现在 wikipedia 上面就有,http://en.wikipedia.org/wiki/Hamming_distance,是 Wegner 1960 年提出的方法,其运算量和最终的 hamming distance 大小成比例,而不是和 bit string 的长度成比例,函数如下:
2014年5月7日星期三
问诊于 UniMelb Health Service
周一就预约了今早 9:45 到 Health Service 问诊,9:30 我就取好钱赶到了 HS,预约是 Dr. Mead,一个慈祥的老人,跟他描述了下症状,说了下我的情况,以及医保规格,Dr. Mead 第一时间就否定了我觉得是胆结石的推断,因为真正的胆结石会非常疼,然后给我按压了下右腹,我没有感觉到哪一块有明显疼痛感,最后有鉴于我的不良饮食习惯,Dr. Mead 觉得可能还是胃的问题,但不会有大问题,然后有鉴于我的医保规格只是 Visitor Budget Cover,他认为我还是先别做 B 超之类的进一步检查,因为做一次就 200 刀,我的医保又报不了,等到下一次又有明显症状的时候再做进一步检查,或者没事的话干脆回国内再做深入检查。Dr. Mead 人还挺好,最后给了我一盒免费的 Rabeprazole Sodium 药,说是他那正好剩了这么一盒,药是没付钱,但问诊费还是缴了 38 刀,也不便宜。总之就这样吧,应该没啥问题。
2014年5月5日星期一
2014年5月4日星期日
散步于午饭后
午饭还是 union house 吃的,依然是素菜加一份 honey chicken,索然无味,鸡肉只吃了一半就作罢了,饭后一人漫步至 museum,看到好几拨小孩子穿着各色的校服在广场和草地上玩耍,天真烂漫,好开心好有活力,在已经步入冬天的情况下,我依然看到很多的小朋友穿着短裤,不论男孩还是女孩,看来老外是从小就很抗冻了。
我有时候在想国内什么时候大家能活的像老外这样闲适悠然,至少他们表面上看上去是那样,有鉴于国内现在的经济发展水平还有势头,我总觉得也许这会很快,但回过头一想,我发现这有可能只是我一厢情愿罢了,老外一直以来就崇尚自由主义,追求个性不盲从,谁比我有钱,谁比我有成就,我一概不在乎,只要我自己活出自己的精彩就行,而国内关于成就关于价值实现似乎有一套普适的标准,大家喜欢基于各种标准进行攀比,谁考了什么学校可以比较比较,谁找了什么工作可以比较比较,谁嫁了什么样的人娶了什么样的人也可以拿来比较比较,大家都在追求别人眼里更好的更体面的东西,却从不停下来问问在自己心里到底什么是真正最想要的,活出自己的精彩也就无从谈起了,所以我想即使国内的发展超过美帝了大家还是会活的忙忙碌碌辛辛苦苦,除非一代人两代人的观念发生根本性的转变。
我有时候在想国内什么时候大家能活的像老外这样闲适悠然,至少他们表面上看上去是那样,有鉴于国内现在的经济发展水平还有势头,我总觉得也许这会很快,但回过头一想,我发现这有可能只是我一厢情愿罢了,老外一直以来就崇尚自由主义,追求个性不盲从,谁比我有钱,谁比我有成就,我一概不在乎,只要我自己活出自己的精彩就行,而国内关于成就关于价值实现似乎有一套普适的标准,大家喜欢基于各种标准进行攀比,谁考了什么学校可以比较比较,谁找了什么工作可以比较比较,谁嫁了什么样的人娶了什么样的人也可以拿来比较比较,大家都在追求别人眼里更好的更体面的东西,却从不停下来问问在自己心里到底什么是真正最想要的,活出自己的精彩也就无从谈起了,所以我想即使国内的发展超过美帝了大家还是会活的忙忙碌碌辛辛苦苦,除非一代人两代人的观念发生根本性的转变。
2014年5月2日星期五
回笼觉的一个梦
早上五点多又是起床拉了一通肚子,看来睡前吃多了李子也是会拉肚子的,之前是杏子,现在换成了李子,哎。
回笼觉睡得还行,只是梦不断,回笼觉的梦一般会记得比较清楚,因为临近起床了。梦见自己好像回到了校园,但具体是和朋友去参加某人婚礼的路上,婚礼的新郎新娘我都不记得认不认识,路上我骑在自行车的方向把上面,双手背在后面控制车的方向,颇有杂耍的感觉,很奇怪为什么会有这么俏皮的行为发生。婚礼过程中有一扇门按照习俗说是不让开的,梦中我有急事想通过这扇门出去却被新人家属阻拦,我向人抱怨新人家属太不讲理,不知变通,就这么个梦,anyway, it's just a dream, let it go。
下面是今天的午餐,小小的丰盛了一下,只是板栗感觉蒸出来还不够好吃,还不知道该怎么正确的加工板栗。

回笼觉睡得还行,只是梦不断,回笼觉的梦一般会记得比较清楚,因为临近起床了。梦见自己好像回到了校园,但具体是和朋友去参加某人婚礼的路上,婚礼的新郎新娘我都不记得认不认识,路上我骑在自行车的方向把上面,双手背在后面控制车的方向,颇有杂耍的感觉,很奇怪为什么会有这么俏皮的行为发生。婚礼过程中有一扇门按照习俗说是不让开的,梦中我有急事想通过这扇门出去却被新人家属阻拦,我向人抱怨新人家属太不讲理,不知变通,就这么个梦,anyway, it's just a dream, let it go。
下面是今天的午餐,小小的丰盛了一下,只是板栗感觉蒸出来还不够好吃,还不知道该怎么正确的加工板栗。
Preston Market 兰州拉面馆
昨天傍晚和翔、康一行三人奔赴 Preston Market 购物,我已是第三次来 Preston 购物了,里面很多华人超市,果蔬很新鲜也很便宜,所以每次都会买很多,这次也不例外,这次还买了一袋板栗打算蒸着吃,其实这次来我最主要的目的还不在于购物,而是来附近的兰州拉面馆吃一回正宗的就蒜拉面,重温下西安老店的味道。
翔说他和 Sophia 每次来得是两人吃一份,因为分量实在是太足了,我听了却很期待,因为我要的就是撑的感觉。。。这次我点的黄焖羊肉拉面,那碗大的,霍,确实够分量,肥美的羊肉也很多,见下图。

最令人惊喜的是面馆居然可以免费提供生蒜,有鉴于猫本这么高的物价,事先着实没有料到可以吃到免费的生蒜,导致我还事先备了一个自带的蒜头,有意思的是当我们向服务员要生蒜时,服务员的表情看上去有点小小的吃惊,估计心想国外还能碰到这么专业的拉面食客,知道就着生蒜吃最美味。
除了主食,另点的三份凉菜分量也很足,一份猪耳朵,一份胡萝卜丝和土豆丝,最后一份花生米,这分量可比上周的台北馆的小菜大多了,唯一不足的是花生米味道稍淡,欠些火候。

昨天的晚饭是真可谓酒足饭饱了,随后的夜生活也很丰富:七点多回到翔家里,打了三个小时的video game,有实况,NBA,Halo 还有街霸。。。玩的挺嗨的,真是一个开心的 Friday evening。
翔说他和 Sophia 每次来得是两人吃一份,因为分量实在是太足了,我听了却很期待,因为我要的就是撑的感觉。。。这次我点的黄焖羊肉拉面,那碗大的,霍,确实够分量,肥美的羊肉也很多,见下图。
最令人惊喜的是面馆居然可以免费提供生蒜,有鉴于猫本这么高的物价,事先着实没有料到可以吃到免费的生蒜,导致我还事先备了一个自带的蒜头,有意思的是当我们向服务员要生蒜时,服务员的表情看上去有点小小的吃惊,估计心想国外还能碰到这么专业的拉面食客,知道就着生蒜吃最美味。
除了主食,另点的三份凉菜分量也很足,一份猪耳朵,一份胡萝卜丝和土豆丝,最后一份花生米,这分量可比上周的台北馆的小菜大多了,唯一不足的是花生米味道稍淡,欠些火候。
2014年4月30日星期三
Melancholy Invasion
气温日降,屋外的一切都提醒着南半球的冬天正悄然来临,穿短袖骑车上下班已经变得越来越不现实了,冬天带来的变化不仅仅是气候上的,更有人心情上的微妙变化,看着草木渐枯黄,感受着阴冷空气,还有每个人脸上都透着的冷漠,我眼中的整个城市都显得颓唐凋败,再想想自己的研究任务和目标,还有不断临近的归期,心里不禁泛起丝丝的忧愁,我期待着突破和压力释放的那一天,希望它就在不远。
2014年4月28日星期一
MPGC 1991 阅读摘录
ABSTRACT
1. For greater flexibility the geometric constraints are treated as weighted observation equations and not as strict conditions.
2. It is proposed to use a Wallis filter for a radiometric equalisation of the image before matching.
3. The Wallis filter has also been used to enhance contrast, high contrast being necessary for accurate matching.
4. A method to derive reasonable approximations by an image pyramid based (coarse-to-fine) approach is presented.
5. The pyramid approach increases the convergence radius (in practical tests parallaxes up to 70 pixels have been handled), convergence rate and computational speed, and can be exploited for a better quality control and self-adaptivity of the algorithm.
6. Without the image pyramid, convergence has been achieved, in some cases, for errors in the approximate values of up to 10-20 pixels, but optimally these approximate values should be 1 pixel accurate.
7. MPGC is a combination of area-based and feature-based, especially edge-based, matching.
8. The theoretical precision of the shifts, in the case of good targets, typically is 0.01-0.05 pixels. The achieved accuracy was for good planar targets 0.2-1 um, for signalised or good natural points 2-3 um, and for natural points on general points on general surfaces 10-15 um, whereby the pixel spacing was typically 10 um. In the performed tests, the matching accuracy was generally similar to the accuracy of manual measurements; in certain cases the matching accuracy was even higher than the manual one. The percentage of blunders automatically detected by MPGC varied from 5%-25% of the total number of points, depending on the image content and object surface. The percentage of undetected blunders was 1%-3% of the points accepted by MPGC as being correct, thus comparable to the error rate of a human operator.
1. For greater flexibility the geometric constraints are treated as weighted observation equations and not as strict conditions.
2. It is proposed to use a Wallis filter for a radiometric equalisation of the image before matching.
3. The Wallis filter has also been used to enhance contrast, high contrast being necessary for accurate matching.
4. A method to derive reasonable approximations by an image pyramid based (coarse-to-fine) approach is presented.
5. The pyramid approach increases the convergence radius (in practical tests parallaxes up to 70 pixels have been handled), convergence rate and computational speed, and can be exploited for a better quality control and self-adaptivity of the algorithm.
6. Without the image pyramid, convergence has been achieved, in some cases, for errors in the approximate values of up to 10-20 pixels, but optimally these approximate values should be 1 pixel accurate.
7. MPGC is a combination of area-based and feature-based, especially edge-based, matching.
8. The theoretical precision of the shifts, in the case of good targets, typically is 0.01-0.05 pixels. The achieved accuracy was for good planar targets 0.2-1 um, for signalised or good natural points 2-3 um, and for natural points on general points on general surfaces 10-15 um, whereby the pixel spacing was typically 10 um. In the performed tests, the matching accuracy was generally similar to the accuracy of manual measurements; in certain cases the matching accuracy was even higher than the manual one. The percentage of blunders automatically detected by MPGC varied from 5%-25% of the total number of points, depending on the image content and object surface. The percentage of undetected blunders was 1%-3% of the points accepted by MPGC as being correct, thus comparable to the error rate of a human operator.
2014年4月25日星期五
ANZAC Day
4月25是澳新军团日(Australian and New Zealand Army Corps),city 里涌现出很多身着军装的大兵和军官,当然还有不少头发花白的估计是参加过越战甚至是二战的老兵,穿着正装,胸前佩着一排排勋章,依然神采奕奕,让人不由心生敬佩。
行至猫本的步行街,发现一对街头艺人周围围满了人,欢快的鼓点节奏还有艺人张扬的发型,以及卖力的表演让不少路人都停下来驻足观看。


在 Swanston St 的北边也有一个街头艺人在表演,一个年轻小伙,单独一人,一架电子琴,看小伙的容貌稍微感觉有点糙,有点凶,但指尖落下,琴声响起的时候真是被震住了,弹得又快又好,只可惜一首还没弹完城管就来了,通知小伙他的时间到了。。。听琴的人群里稍微能听到嘘声表示不满,但猫本城管的执法过程还算平和。

在 Flinders 火车站的东边有一个 Public Bar,里面聚集了很多水手大兵在畅饮啤酒庆祝节日。


下午两点半坐电车来到 South Wharf,驻足亚拉河上,远眺猫本 CBD 慨叹澳洲的空气质量真是好,真希望不久的将来国内也能有这样一片干净的蓝天。下午在 South Wharf 买了两条 Levi's 的牛仔裤,一条 32/32 skinny fit,一条 30/32 regular fit,挑了个把小时,试了有十几条裤子才最终选定这两条,本来看上一条 regular tapered fit,穿着特舒服,颜色也好看,可惜最小只剩下 32/32 的,估计能有 31/32 的就合身了,可惜了。价钱还不错,两条一起 98 刀,比国内 Levi's 的牛仔裤可是便宜太多了。

行至猫本的步行街,发现一对街头艺人周围围满了人,欢快的鼓点节奏还有艺人张扬的发型,以及卖力的表演让不少路人都停下来驻足观看。
在 Flinders 火车站的东边有一个 Public Bar,里面聚集了很多水手大兵在畅饮啤酒庆祝节日。
2014年4月18日星期五
舌尖上的中国 第二季 开播
昨天晚上北京时间9:10中央一套开播 舌尖上的中国第二季,我是到今天上午才看的视频。第二季的第一集名为 脚步,分好几个主线展开,包括采蜂蜜的人,养蜂人,还有渔民等,明显感觉第二季里面融入了更多的人物本身的故事,有更浓的人情味,有些情节和旁白更是催人泪下。看了舌尖上的中国最大的感受就是要珍惜食物,想想自己吃的美味从原食材到加工烹饪都是凝聚了很多人的辛勤劳动的汗水,至此对 谁知盘中餐粒粒皆辛苦 这句话有了更深的理解。很高兴舌尖二开播了,每周又多了一个可以看的节目了。

2014年4月17日星期四
Gabriel Garcia Marquez
早上醒来的时候,习惯性的拿起手机看新闻,一打开凤凰网就看到《百年孤独》的作者,文学巨匠加西亚马尔克斯去世了,尽管马尔克斯确实年事已高,又早就诊断患有癌症,而且早已封笔多年,但看到新闻的那一刻还是感到无比的惋惜,仿佛他的离去意味着一个时代的终结。
我看过的书并不多,屈指可数,马尔克斯的《百年孤独》和《霍乱时期的爱情》是其中的两本,马尔克斯的作品我也就看过这两本,但都看的很深很认真。
想起自己第一次尝试看《百》的时候还是在高中的时候,当时还没有真正喜欢上阅读,没有欣赏文字的能力,只是跟风看看文学作品,一上来我就从图书馆借了一本《百》,结果没坚持过两天就作罢了,被里面光怪陆离的情节,盘根错节的人物关系以及模糊不清的人物名称给彻底打败了,竟然爷孙好几代人都叫阿尔卡迪奥和奥雷里亚诺。。。打那以后近10年都没敢再尝试阅读《百》,一直到2010年的夏天,我发现亚马逊上有马尔克斯正式授权发布的《百》的中文版在热卖,当时想想一定要挑战一下自己,而且10年的人生历练让我相信自己慢慢的开始能读懂《百》了,于是毫不犹豫的下了单,并且在接下来两个月的时间里认认真真把它品尝了一遍。

在读完《百》合上书本的那一刻我真的有种像是被人从马孔多硬生生拉回到现实的感觉,恍如隔世,像是自己和书中的主角捆绑在一起在马孔多风雨飘摇的几百年里历经了几代人的生死轮回荣辱兴衰一样,沉醉了,这就是马尔克斯那有魔力般文字的力量,我热爱电影,但还没有哪部电影能带给我这样的感官冲击。
写着写着我决定找时间再重读一遍《百年孤独》,肯定还会读一读马尔克斯其它的作品吧,当然如果这些作品都是正版的话,我想这应该也就是缅怀马尔克斯最好的方式了吧,但愿马尔克斯在天国找到属于他的那个马孔多,一个能多些阳光少些阴雨的马孔多。

我看过的书并不多,屈指可数,马尔克斯的《百年孤独》和《霍乱时期的爱情》是其中的两本,马尔克斯的作品我也就看过这两本,但都看的很深很认真。
想起自己第一次尝试看《百》的时候还是在高中的时候,当时还没有真正喜欢上阅读,没有欣赏文字的能力,只是跟风看看文学作品,一上来我就从图书馆借了一本《百》,结果没坚持过两天就作罢了,被里面光怪陆离的情节,盘根错节的人物关系以及模糊不清的人物名称给彻底打败了,竟然爷孙好几代人都叫阿尔卡迪奥和奥雷里亚诺。。。打那以后近10年都没敢再尝试阅读《百》,一直到2010年的夏天,我发现亚马逊上有马尔克斯正式授权发布的《百》的中文版在热卖,当时想想一定要挑战一下自己,而且10年的人生历练让我相信自己慢慢的开始能读懂《百》了,于是毫不犹豫的下了单,并且在接下来两个月的时间里认认真真把它品尝了一遍。
在读完《百》合上书本的那一刻我真的有种像是被人从马孔多硬生生拉回到现实的感觉,恍如隔世,像是自己和书中的主角捆绑在一起在马孔多风雨飘摇的几百年里历经了几代人的生死轮回荣辱兴衰一样,沉醉了,这就是马尔克斯那有魔力般文字的力量,我热爱电影,但还没有哪部电影能带给我这样的感官冲击。
写着写着我决定找时间再重读一遍《百年孤独》,肯定还会读一读马尔克斯其它的作品吧,当然如果这些作品都是正版的话,我想这应该也就是缅怀马尔克斯最好的方式了吧,但愿马尔克斯在天国找到属于他的那个马孔多,一个能多些阳光少些阴雨的马孔多。
2014年4月15日星期二
Guangzhou Ever Grand vs Melbourne Victory at Etihad Stadium
第一次在猫本看亚冠的比赛,记得上一次在现场看球都是2011年时候的事情了,当时在贺龙体育场看的长沙金德对上海申花。
入场前料想会有很多中国球迷到场观战,但实在是没想到会有这么多,中国球迷的红色球衣在观众席的一边连成了红色的海洋,另外还有很多球迷散落在其它看台区域,我估计在场的中国球迷人数是要多过猫本当地球迷的,不可谓声势浩大,有种来到了广州天体的感觉。但是我想说的是,猫本球迷人数虽略少,但有好几个集中的球迷方阵,喊着统一的口号,踏着统一的节奏,非常团结,助威气势一点不弱于人数众多的中国球迷,其实我在现场的感觉是猫本球迷的气势很多时候都盖过了中国球迷,可能中国球迷还需要更为专业激情的组织一下吧。

下图是猫本球迷冲中国球迷竖中指对骂。。。


上图是几个光头本土球迷加油助威,下图是另一个本土球迷方阵。



最后来一张中国红色海洋,辛苦了大家。

入场前料想会有很多中国球迷到场观战,但实在是没想到会有这么多,中国球迷的红色球衣在观众席的一边连成了红色的海洋,另外还有很多球迷散落在其它看台区域,我估计在场的中国球迷人数是要多过猫本当地球迷的,不可谓声势浩大,有种来到了广州天体的感觉。但是我想说的是,猫本球迷人数虽略少,但有好几个集中的球迷方阵,喊着统一的口号,踏着统一的节奏,非常团结,助威气势一点不弱于人数众多的中国球迷,其实我在现场的感觉是猫本球迷的气势很多时候都盖过了中国球迷,可能中国球迷还需要更为专业激情的组织一下吧。
下图是猫本球迷冲中国球迷竖中指对骂。。。
上图是几个光头本土球迷加油助威,下图是另一个本土球迷方阵。
最后来一张中国红色海洋,辛苦了大家。
2014年4月14日星期一
留学期间阅读的文献汇总,二季度
1. Photo Tourism: Exploring Photo Collections in 3D, (completely read on 27th Mar 2014).
University of Washington 的 Noah Snavely 和 Steven M. Seitz 在 2006 年发表于 Association for Computing Machinery (ACM) 的一篇文章。看这篇文章主要的获得是吸纳了其中关于 Structure from Motion 流程的文字描述,其实这篇文章本身主要的内容还是关于如何利用互联网上的大数据(这里指海量图片数据)来对一些著名的自然和人文景点进行三维重建,并且提 出一整套关于某个景点的图像浏览导航的策略,让人们可以通过互联网的图片来进行虚拟的景点观光,并且可以通过重建出来的各图像拍摄的时间和位置,最后统计 总结出最佳的图像浏览顺序,我想 Google 地图的街景浏览技术应该就是用的这篇文章里描述的技术,包括你按下方向键,Google map 是通过一种渐变的方式过渡到下一幅图像的,但 Google 街景浏览应该还不是利用的三维重建出来的结果,而是实地拍摄的大量图片。这篇文章里主要涉及的还是基于特征的稀疏重建,并不是密集重建结果,而是利用稀疏 的重建点云去拟合各个平面,最后用平面去描述场景,这对于建筑一类的场景还是奏效的。
文中关于 SfM 的过程主要是进行的文字描述,我发现 SfM 跟我 3 月初的做法最大的不同就在于其在起始对每个图像对都首先进行了特征匹配,这样所有的图像间的关系就建立好了,各图像上匹配成 Tracks 的特征点也从此有了一个全局的对应关系,而不是像我的做法中的那样某个图像中的特征点必须通过和某个已经定向好的图像进行特征匹配才能建立其和全局点云的 对应关系,这样的做法确实更为合理和鲁棒。
2. Scene Reconstruction and Visualization From Community Photo Collections, (completely read on 30th Mar 2014).
这是上文作者 Noah Snavely 2010 年发表于 Proceedings of the IEEE 的一篇综述性的文章,主要是关于 Recent progress in digitizing and visualizing the world from data captured by people taking photos and uploading them to the web。
文章从基于特征的 Structure from Motion 场景稀疏重建讲起,接着讲到场景的密集重建,然后很大篇幅都是讲什么场景总结、图像聚类、寻找最优浏览路径等,也就是跟上文 Photo Tourism 相关的那些技术,跟我的研究相关度不高。文章中说到他们场景重建的目的不仅仅是通过 Multi-view stereo 来恢复场景的几何,还要恢复每个场景点的光照反射以及场景中的光照条件,这其实才是完整的三维重建要最终达到的效果,其实我一直认为考虑了光照条件和反射的同时也可以提高场景几何重建的精度,而不单单是先完成几何重建,完了之后再单独去进行光照和反射重建。
下面再摘录一些我认为文中对我的研究会有意义的信息:
M. Goesele 和 N. Snavely 于 2007 年发表于 ICCV 的 Multi-view stereo for community photo collections,里面有提出depth maps fusion 的方法,这篇文章我决定这两天好好看看。
文中提到其 SfM 后形成的 Image connectivity graph 是由 neato tool in the Graphviz graph visualization toolkit [25] 画出的,这个先记着,说不定后面可以用上。
文章将场景材料分为 diffuse, glossy and mirror 三种,即漫反射,有一定反射能力以及全镜面反射三种,然后还引用了 3 篇实验室内标定场景反射能力的文章,参考文中的 [13] [38] [46],还提到 3 篇室外估计光照和反射的文章,参考文中的 [12] [14] [78]。然后 本文作者一干人等在 2009 年文献 [27] 中使用 computer graphics 领域中的 inverse rendering 技术来从社区图像集中获得环境光照和反射。
3. Multi-View Stereo for Community Photo Collections, (completely read on 30th Mar 2014).
这就是上文中提到的 [22] 号参考文献,M. Goesele 和 N. Snavely 于 2007 年发表于 ICCV 的一篇文章。首先纠正一个说法,总结上文时我说该文里提到了新的 depth maps fusion 的算法,其实严格意义上来说本文并不是关于 depth maps fusion 的。
我就直接开始总结本文的核心思想吧,在 SfM 之后,在一堆网络图片中,首先文章先后通过全局选择准则 Global View Selection 和局部选择准则 Local View Selection 自动的选择适合进行后续 MVS 的各图像集,形成的每个图像集保证其各图像拍摄的场景内容 scene content,外形光照 appearance, 还有尺度 scale 都差不多一致,还有图像集中各图像对之间有一定的基线长度,而不至于基线太短,文中的 Global and Local View Selection 准则分别都有详细的式子描述,但这个不是我关心的重点。我关心的重点是后续在每个图像集上进行 MVS 的算法。
文中形成的每个图像集都有一个 reference image,最后要达到的效果是每个图像集都要形成一幅相对于其参考图像的 depth map,每个图像集的 depth map 是通过一种 seeds expansion 的策略去形成的:
一、相对于参考图像的 depth map 的形成过程中一直维护有一个优先级队列 Q,存放了接下来要进行评估考察的参考图像中的候选像素的位置,以及初始的深度值与法向值,这些 candidates 在 Q 中是按其期望置信度(即与其相邻的,将其引荐入 Q 的像素的置信度)大 小排列的,期望置信度高的候选者将被优先评估;通过了评估考察的候选者将被正式存入输出的 depth map, normal map and confidence map,并且将其 4 邻域内的 4 个像素作为新的候选者载入 Q,这 4 个候选者的期望置信度就是该通过评估考察的像素的置信度;
二、初始化优先级队列 Q,很显然在 SfM 过程中通过高精度配上的那些参考图中的稀疏 feature points 可以作为 seeds 推入 Q,并被优先考察,文中还指出可以把所有能在参考图上形成合理投影像点的已重建出来的稀疏场景点在参考图上做投影,并把投影像点作为 seeds 推入 Q,即使很多点在 SfM 过程中并没被裁定能在参考图中被观测到,如此一来初始 seeds set 就得到了拓展,反正那些确实在参考图中被遮挡的 feature points 在后续过程中很有可能因为通不过 photometric consistency check 而被否决掉。然后每个初始 seeds 的深度就设置为其重建出来的深度,法向为 fronto-parallel normal;
三、Stereo Matching as Optimization,基于优化的立体匹配,这一部分是文章的精髓所在。文章把场景的最小基元描述成一个带有法向的平面,当然这个法向是相对于参考图 而言的,以每个像素为中心的 N*N 的像素矩形框对应了场景中的一个有 N*N 个采样点的有法向的空间平面,如下图所示。
 然后像素点 (s,t) 对应的场景点坐标就可以表示为:
然后像素点 (s,t) 对应的场景点坐标就可以表示为:
 而以 (s,t) 为中心的 N*N 的矩形框中的每个像素对应的场景点坐标就可以表示为:
而以 (s,t) 为中心的 N*N 的矩形框中的每个像素对应的场景点坐标就可以表示为:
 其中 hs(s,t) 和 ht(s,t) 为平面深度在 s 和 t 方向上的线性增长因子,他们共同表示了平面法向 n。如此一来 N*N
个像素矩形框对应的 N*N
个空间平面点的坐标也就全都可以计算出来了,有了这些坐标,然后结合其它图像各自的参数就可以让这些平面点在其它图像上进行重投影,并对重投影像点的
color 进行插值,从而在每个其它每个图像上得到一个 N*N 的 image patch 来,利用这些 patches 和参考图上的
patch 来一一计算 SSD (Sum of Squared Differences),并考察相似性程度。
其中 hs(s,t) 和 ht(s,t) 为平面深度在 s 和 t 方向上的线性增长因子,他们共同表示了平面法向 n。如此一来 N*N
个像素矩形框对应的 N*N
个空间平面点的坐标也就全都可以计算出来了,有了这些坐标,然后结合其它图像各自的参数就可以让这些平面点在其它图像上进行重投影,并对重投影像点的
color 进行插值,从而在每个其它每个图像上得到一个 N*N 的 image patch 来,利用这些 patches 和参考图上的
patch 来一一计算 SSD (Sum of Squared Differences),并考察相似性程度。
文中为了应对不同视角法向造成的灰度差,在考查相似性程度的时候,还为每个其它图像加入了一个线性尺度参数 ck,文中说 ck 因子很好的描述了在恒定光照条件下,漫反射空间平面在不同视角图像上的色彩变化,如此一来总的相似性描述方程应该为:
 忽略 (s,t) 坐标上式就变成:
忽略 (s,t) 坐标上式就变成:
 忽略 (s,t) 坐标上式就变成:
忽略 (s,t) 坐标上式就变成:
 按照上述模型,如果有 m 幅其它图像的话,那么优化过程中就有 3+3m 个变量,h,hs,ht,以及 3m 个
ck,而如果是彩色图像,那么每个采样点有 3 个上述的观测方程,整个 patch 的话就是 3n*n 个,然后有 m 幅图像,因此总共有
3n*n*m 个观测方程,所以是超定的。文中采用摄影测量领域的 Multiphoto Gemetrically Constrained
Least Squares Matching (MPGC) 来做这一优化。
按照上述模型,如果有 m 幅其它图像的话,那么优化过程中就有 3+3m 个变量,h,hs,ht,以及 3m 个
ck,而如果是彩色图像,那么每个采样点有 3 个上述的观测方程,整个 patch 的话就是 3n*n 个,然后有 m 幅图像,因此总共有
3n*n*m 个观测方程,所以是超定的。文中采用摄影测量领域的 Multiphoto Gemetrically Constrained
Least Squares Matching (MPGC) 来做这一优化。
下面摘录一段文中有关采用 SSD 还是 NCC 来做相似性度量的描述,讲的很好:

4. Accurate Multi-View Reconstruction Using Robust Binocular Stereo and Surface Meshing, (completely read on 3rd Apr 2014).
这是 University of British Columbia 的 Derek Brakley 在 2008 年发表于 CVPR 的一篇文章,当时被这篇文章吸引,是因为看到了其中几张枕头和衣服袖子的重建结果非常的好,心想要了解下到底用了什么方法,今天看完,一个总的感受就是这 篇文章之所以能有好的结果就在于他采用了很多道繁琐的工序来剔除 outliers,也就是说质量控制比较好,但我很怀疑他的整套算法的运行速度真的能像文中说的那么快。
直接切入重点,开始总结其中的一些关键点,首先总结下文中算法的整体流程:
一、需要提一下的是所有的图像都是事先标定好的,我看文中重建的物体都是放在一个贴满编码标志的平面板上用以标定图像外参数,然后文中上来就说物体 的轮廓已给定。。。也就是说 visual hull 已经有了,这样的条件一给定就已经能排除大量位于 visual hull 外的 outliers 了。。。回到正题,算法先选定几组靠的比较近的,适合进行 binocular stereo 的图像对,然后在每个图像对上去做 binocular stereo,并各自生成 depth maps,并整合 “merging” 成一个单一的大的 depth map,注意这里的 merging 没有 fusion 的意思,而只是单纯的把所有的 depth maps 整合成一大的,这一步得到的点云集为 Pn,其中文中还对每个点估计了其法向;
二、文中称这一步为 downsampling,降采样,意思就是上一步 merge 成的大 depth map 对于每个场景点都很多采样点,重复观测等,冗余度很大,这是很自然的,其实这一步就是 depth fusion,这一步输出的点云集为 Ps;
三、Cleaning,在完成 depth fusion 的 cloud points 中去进一步剔除 outliers 和小尺度的高频噪声点,这一步输出的点云集为 Pf;
四、Meshing,形成三角网络 mesh。
第一步中,文中的主要亮点在于所谓的 Scaled window matching,由于文中的密集匹配方法还是基于 NCC,所以避免不了要解决模板匹配中的 fronto-parallel 的问题,文中解决这一问题的方法就是在 epipolar resampling 也就是 stereo rectify 过程中生成多个不同水平矫正尺度(different horizontal scale factors)的匹配图像,然后用参考图的同一个模板在这不同矫正尺度的匹配图上沿极线去找最优匹配位置,文中花了1/4页的版面去证明这个尺度比例在 整幅图上是不变的,然后最后又说其实就选择了 3 个固定的水平尺度因子去进行矫正 1/sqrt(2), 1 以及 sqrt(2)。。。然后是亚像素视差的获得,我的理解好像是他要对图像进行拓展,比方说沿水平方向把图像尺寸进行插值拓展,然后用拓展的图去估计亚像素 视差。。。这个方法我不敢恭维啊。最后在视差图上还进行了一次中值滤波和 standard bilateral filter weighted by the NCC value 以剔除高频噪声视差点。
在所有的 depth maps 反投影到场景空间形成整合的大的点云之后,由于后续的处理需要用到点云中点的法向,因此还需要估计每个点的法向值,文中提到这可以使用 image-space gradient calculation 来估计每个 depth maps 中每个像素相对于该 depth map 的法向,这其实就是上文中的平面 patch 表示平面法向的方式,然后文中采用的方式是通过 kD-Tree 找到每个空间点的 k 个邻近点,然后去估计该点和 k 个邻近点张开的空间范围的最次的主方向,也就是对应了最小特征值的特征向量,文中描述这一过程是一 Principal Component Analysis (PCA) [20] 过程,这一术语用的真好,其实这一步出来的法向还不能确定正负号,然后就利用图像和观测场景点之间的相互关系来确定最终的法向方向,因为某观测到的场景点的法向肯定是冲着图像的,而不能是背着图像的。有了每个点的法向之后,这就形成了点云集 Pn。
到这一步就需要开始 fusion 点云了,他这里的做法简而言之,就是先对 Pn 进行聚类,聚为一类的空间点被认为是对应了同一个空间点,然后在每一类中选一个代表出来代表该类,这就完成了 fusion 了,他采用的聚类方法是所谓的 hierarchical vertex clustering,然后要支持该层次聚类还需要特别的数据结构 hierarchical partioning structure,文中选择了其中的 Volume-Surface Tree [5] 结构。最后每个聚类中的代表是怎么选举出来的呢?其实就是取的聚类中所有点的平均点位和平均法向作为该聚类代表。



















文章在其摘要中就声称该算法主要是面向三维医学数据,像核磁共振成像扫描得到的人体三维图像切片等,这种医学数据就是典型的三维离散数据,里面的单元是一个一个 voxel,也就是三维像素,每个 voxel 也有一个强度值,也就是 intensity,原文中说成是 density。我记得以前张老师叫我处理过一组这样的脑部切片图像,它里面不同的人体组织有不同的灰度值,骨骼一般灰度值比较高,软组织灰度值就比较低,显得较暗,但同一组织在不同切片图像上的灰度响应是一致的,比方说我们想从这样的三维数据中提取出整个人体骨骼的 surface,已知骨骼外边缘的灰度值恒为 255,那么我们就只需把每个切片图像中灰度值为 255 的像素取出来就行了,但是简单的这样做只能是得到彼此不相关联的一个个封闭的 curves,不在相邻切片图像间建立联系的话就这些独立的 curves 是无法重构出骨骼 surface 的,那么文章的方法就是每次同时考虑相邻的两层切片图像,上下对应各取 2×2=4 个像素,共 8 个像素组成一个 cube,这 8 个像素每个像素都和骨骼的灰度 255 去比较,也就是说每个像素会有 0 和 1 两种状态,真正的 bone surface 会切过该 cube 中那些一端灰度比 255 小,一端比 255 大的边,这个还是比较好理解的。
文中对 surface 和 cube 相交的形式总结归纳出了一下 15 种:

其中第 0 种就是没有 surface,第 1 种里面 surface 可以用 1 个 triangle 表示,其它的形式中 surface 最多可以用 4 个 triangles 来表示,每个 triangle 的 vertices 的三维坐标可以利用所在边两端像素的灰度简单的线性插值出来,也就是说每个确定包含 bone surface 的 cube 可以最多输出 4 个 triangles,最终遍历所有 voxels 以后所有的 triangles 将自然连接成一个完整的 triangle mesh,也就是我们想要的 bone surface。
University of Washington 的 Noah Snavely 和 Steven M. Seitz 在 2006 年发表于 Association for Computing Machinery (ACM) 的一篇文章。看这篇文章主要的获得是吸纳了其中关于 Structure from Motion 流程的文字描述,其实这篇文章本身主要的内容还是关于如何利用互联网上的大数据(这里指海量图片数据)来对一些著名的自然和人文景点进行三维重建,并且提 出一整套关于某个景点的图像浏览导航的策略,让人们可以通过互联网的图片来进行虚拟的景点观光,并且可以通过重建出来的各图像拍摄的时间和位置,最后统计 总结出最佳的图像浏览顺序,我想 Google 地图的街景浏览技术应该就是用的这篇文章里描述的技术,包括你按下方向键,Google map 是通过一种渐变的方式过渡到下一幅图像的,但 Google 街景浏览应该还不是利用的三维重建出来的结果,而是实地拍摄的大量图片。这篇文章里主要涉及的还是基于特征的稀疏重建,并不是密集重建结果,而是利用稀疏 的重建点云去拟合各个平面,最后用平面去描述场景,这对于建筑一类的场景还是奏效的。
文中关于 SfM 的过程主要是进行的文字描述,我发现 SfM 跟我 3 月初的做法最大的不同就在于其在起始对每个图像对都首先进行了特征匹配,这样所有的图像间的关系就建立好了,各图像上匹配成 Tracks 的特征点也从此有了一个全局的对应关系,而不是像我的做法中的那样某个图像中的特征点必须通过和某个已经定向好的图像进行特征匹配才能建立其和全局点云的 对应关系,这样的做法确实更为合理和鲁棒。
2. Scene Reconstruction and Visualization From Community Photo Collections, (completely read on 30th Mar 2014).
这是上文作者 Noah Snavely 2010 年发表于 Proceedings of the IEEE 的一篇综述性的文章,主要是关于 Recent progress in digitizing and visualizing the world from data captured by people taking photos and uploading them to the web。
文章从基于特征的 Structure from Motion 场景稀疏重建讲起,接着讲到场景的密集重建,然后很大篇幅都是讲什么场景总结、图像聚类、寻找最优浏览路径等,也就是跟上文 Photo Tourism 相关的那些技术,跟我的研究相关度不高。文章中说到他们场景重建的目的不仅仅是通过 Multi-view stereo 来恢复场景的几何,还要恢复每个场景点的光照反射以及场景中的光照条件,这其实才是完整的三维重建要最终达到的效果,其实我一直认为考虑了光照条件和反射的同时也可以提高场景几何重建的精度,而不单单是先完成几何重建,完了之后再单独去进行光照和反射重建。
下面再摘录一些我认为文中对我的研究会有意义的信息:
M. Goesele 和 N. Snavely 于 2007 年发表于 ICCV 的 Multi-view stereo for community photo collections,里面有提出depth maps fusion 的方法,这篇文章我决定这两天好好看看。
文中提到其 SfM 后形成的 Image connectivity graph 是由 neato tool in the Graphviz graph visualization toolkit [25] 画出的,这个先记着,说不定后面可以用上。
文章将场景材料分为 diffuse, glossy and mirror 三种,即漫反射,有一定反射能力以及全镜面反射三种,然后还引用了 3 篇实验室内标定场景反射能力的文章,参考文中的 [13] [38] [46],还提到 3 篇室外估计光照和反射的文章,参考文中的 [12] [14] [78]。然后 本文作者一干人等在 2009 年文献 [27] 中使用 computer graphics 领域中的 inverse rendering 技术来从社区图像集中获得环境光照和反射。
3. Multi-View Stereo for Community Photo Collections, (completely read on 30th Mar 2014).
这就是上文中提到的 [22] 号参考文献,M. Goesele 和 N. Snavely 于 2007 年发表于 ICCV 的一篇文章。首先纠正一个说法,总结上文时我说该文里提到了新的 depth maps fusion 的算法,其实严格意义上来说本文并不是关于 depth maps fusion 的。
我就直接开始总结本文的核心思想吧,在 SfM 之后,在一堆网络图片中,首先文章先后通过全局选择准则 Global View Selection 和局部选择准则 Local View Selection 自动的选择适合进行后续 MVS 的各图像集,形成的每个图像集保证其各图像拍摄的场景内容 scene content,外形光照 appearance, 还有尺度 scale 都差不多一致,还有图像集中各图像对之间有一定的基线长度,而不至于基线太短,文中的 Global and Local View Selection 准则分别都有详细的式子描述,但这个不是我关心的重点。我关心的重点是后续在每个图像集上进行 MVS 的算法。
文中形成的每个图像集都有一个 reference image,最后要达到的效果是每个图像集都要形成一幅相对于其参考图像的 depth map,每个图像集的 depth map 是通过一种 seeds expansion 的策略去形成的:
一、相对于参考图像的 depth map 的形成过程中一直维护有一个优先级队列 Q,存放了接下来要进行评估考察的参考图像中的候选像素的位置,以及初始的深度值与法向值,这些 candidates 在 Q 中是按其期望置信度(即与其相邻的,将其引荐入 Q 的像素的置信度)大 小排列的,期望置信度高的候选者将被优先评估;通过了评估考察的候选者将被正式存入输出的 depth map, normal map and confidence map,并且将其 4 邻域内的 4 个像素作为新的候选者载入 Q,这 4 个候选者的期望置信度就是该通过评估考察的像素的置信度;
二、初始化优先级队列 Q,很显然在 SfM 过程中通过高精度配上的那些参考图中的稀疏 feature points 可以作为 seeds 推入 Q,并被优先考察,文中还指出可以把所有能在参考图上形成合理投影像点的已重建出来的稀疏场景点在参考图上做投影,并把投影像点作为 seeds 推入 Q,即使很多点在 SfM 过程中并没被裁定能在参考图中被观测到,如此一来初始 seeds set 就得到了拓展,反正那些确实在参考图中被遮挡的 feature points 在后续过程中很有可能因为通不过 photometric consistency check 而被否决掉。然后每个初始 seeds 的深度就设置为其重建出来的深度,法向为 fronto-parallel normal;
三、Stereo Matching as Optimization,基于优化的立体匹配,这一部分是文章的精髓所在。文章把场景的最小基元描述成一个带有法向的平面,当然这个法向是相对于参考图 而言的,以每个像素为中心的 N*N 的像素矩形框对应了场景中的一个有 N*N 个采样点的有法向的空间平面,如下图所示。
文中为了应对不同视角法向造成的灰度差,在考查相似性程度的时候,还为每个其它图像加入了一个线性尺度参数 ck,文中说 ck 因子很好的描述了在恒定光照条件下,漫反射空间平面在不同视角图像上的色彩变化,如此一来总的相似性描述方程应该为:
下面摘录一段文中有关采用 SSD 还是 NCC 来做相似性度量的描述,讲的很好:
文中还花了较多篇幅描述采用怎么的优化机制去避免 MPGC 发生震荡,看着还挺繁琐的。
这是 University of British Columbia 的 Derek Brakley 在 2008 年发表于 CVPR 的一篇文章,当时被这篇文章吸引,是因为看到了其中几张枕头和衣服袖子的重建结果非常的好,心想要了解下到底用了什么方法,今天看完,一个总的感受就是这 篇文章之所以能有好的结果就在于他采用了很多道繁琐的工序来剔除 outliers,也就是说质量控制比较好,但我很怀疑他的整套算法的运行速度真的能像文中说的那么快。
直接切入重点,开始总结其中的一些关键点,首先总结下文中算法的整体流程:
一、需要提一下的是所有的图像都是事先标定好的,我看文中重建的物体都是放在一个贴满编码标志的平面板上用以标定图像外参数,然后文中上来就说物体 的轮廓已给定。。。也就是说 visual hull 已经有了,这样的条件一给定就已经能排除大量位于 visual hull 外的 outliers 了。。。回到正题,算法先选定几组靠的比较近的,适合进行 binocular stereo 的图像对,然后在每个图像对上去做 binocular stereo,并各自生成 depth maps,并整合 “merging” 成一个单一的大的 depth map,注意这里的 merging 没有 fusion 的意思,而只是单纯的把所有的 depth maps 整合成一大的,这一步得到的点云集为 Pn,其中文中还对每个点估计了其法向;
二、文中称这一步为 downsampling,降采样,意思就是上一步 merge 成的大 depth map 对于每个场景点都很多采样点,重复观测等,冗余度很大,这是很自然的,其实这一步就是 depth fusion,这一步输出的点云集为 Ps;
三、Cleaning,在完成 depth fusion 的 cloud points 中去进一步剔除 outliers 和小尺度的高频噪声点,这一步输出的点云集为 Pf;
四、Meshing,形成三角网络 mesh。
第一步中,文中的主要亮点在于所谓的 Scaled window matching,由于文中的密集匹配方法还是基于 NCC,所以避免不了要解决模板匹配中的 fronto-parallel 的问题,文中解决这一问题的方法就是在 epipolar resampling 也就是 stereo rectify 过程中生成多个不同水平矫正尺度(different horizontal scale factors)的匹配图像,然后用参考图的同一个模板在这不同矫正尺度的匹配图上沿极线去找最优匹配位置,文中花了1/4页的版面去证明这个尺度比例在 整幅图上是不变的,然后最后又说其实就选择了 3 个固定的水平尺度因子去进行矫正 1/sqrt(2), 1 以及 sqrt(2)。。。然后是亚像素视差的获得,我的理解好像是他要对图像进行拓展,比方说沿水平方向把图像尺寸进行插值拓展,然后用拓展的图去估计亚像素 视差。。。这个方法我不敢恭维啊。最后在视差图上还进行了一次中值滤波和 standard bilateral filter weighted by the NCC value 以剔除高频噪声视差点。
在所有的 depth maps 反投影到场景空间形成整合的大的点云之后,由于后续的处理需要用到点云中点的法向,因此还需要估计每个点的法向值,文中提到这可以使用 image-space gradient calculation 来估计每个 depth maps 中每个像素相对于该 depth map 的法向,这其实就是上文中的平面 patch 表示平面法向的方式,然后文中采用的方式是通过 kD-Tree 找到每个空间点的 k 个邻近点,然后去估计该点和 k 个邻近点张开的空间范围的最次的主方向,也就是对应了最小特征值的特征向量,文中描述这一过程是一 Principal Component Analysis (PCA) [20] 过程,这一术语用的真好,其实这一步出来的法向还不能确定正负号,然后就利用图像和观测场景点之间的相互关系来确定最终的法向方向,因为某观测到的场景点的法向肯定是冲着图像的,而不能是背着图像的。有了每个点的法向之后,这就形成了点云集 Pn。
到这一步就需要开始 fusion 点云了,他这里的做法简而言之,就是先对 Pn 进行聚类,聚为一类的空间点被认为是对应了同一个空间点,然后在每一类中选一个代表出来代表该类,这就完成了 fusion 了,他采用的聚类方法是所谓的 hierarchical vertex clustering,然后要支持该层次聚类还需要特别的数据结构 hierarchical partioning structure,文中选择了其中的 Volume-Surface Tree [5] 结构。最后每个聚类中的代表是怎么选举出来的呢?其实就是取的聚类中所有点的平均点位和平均法向作为该聚类代表。
上一步得到 Ps 之后,其中还有很多 outliers 和 small scale high frequency noise,这一部分文章怎么做的我没看太明白,也没有看太细,就是看到处理前者是采用的迭代分类的方式,然后算了一个 Plane Fit Criterion [42],就可以检测到 outliers 了。滤除高频噪声文中采用一种 point-normal filtering inspired by Amenta and Kil [3] and is basically a simplification of the Moving Least Square Projection [1] using the per-sample normal estimate,我大概的理解是利用邻近点进行加权拟合得到一个平面,然后让点在该平面上做投影,并用投影点代替该点。
最后关于 Mesh,我涉及的不多,所以也没怎么看懂,大概的意思就是要做到两点吧,先是把传统的 delaunay triangulation
改了下,改成局部的 triangulation
了,之前是全局形式的,现在改成局部的话,不会牵一发而动全身了,提高了速度,另一个就是争取降维,做 2D 的 delaunay
triangulation 简化算法。在 meshing 过程中文章也有剔除的操作。
5. Accurate, Dense, and Robust Multiview Stereopsis, (completely read on 1st May 2014).
我崇拜的大牛 Y. Furukawa 在 2010 年发表在 PAMI 的一篇文章,详细介绍了他的 PMVS 的整套方法原理
6. SURE: Photogrammetric Surface Reconstruction from Imagery, (completely read on 6th May 2014).
这是来自 Institute for Photogrammetry, University of Stuttgart 的 Mathias Rothermel, K. Wenzel, D. Fritsch 和 N. Haala 的一篇文章,说是一篇学术文章哈,其实主要是介绍他们的 SURE 三维重建软件的原理。
前言部分总结说虽然已经有很多的 MVS 算法提出,但是真正公开让大家可以用到的 MVS 软件却还很少,里面提到了 Furukawa 的 PMVS 还有 CMVS,这两个都是可以在 Furukawa 网站上下到的,还有就是基于最大流/最小割全局方法的 MicMac 软件。文章的前言还是很丰富的,有一页半的量,总结了很多相关的文章,后面自己写文章值得参考。
文章的 SURE 软件的核心算法其实就是 Hirschmuller 的 Semi global matching,然后作为对软件的介绍,文章把软件的四大功能模块及相应的输入输出接口通过下面的流图表示出来了。
这个流程现在看还是比较清楚的,需要说明的是 SURE 并不是为每幅图像都生成一幅视差图并最终融合到一起,而是基于一定的机制,比方说按 EO 连通性对图像进行聚类,每一类选出一个 reference image,这就是 module 1 的工作;然后每一个聚类里其它图像都和参考图像组成一个 binocular stereo model 去做 tSGM,得到很多幅相对于该参考图像的视差图,当然这些视差图肯定是通过了 left/right consistency check 的视差图,这就是 module 2 和 3 的工作;最后就是通过这多个相对于参考图像的视差图基于 multi-view geometrical consistency check 来进行进一步的粗差剔除,深度融合以及最终非线性优化形式的 triangulation 的操作得到最终的相对于该聚类中参考图像的完整深度图,这就是 module 4 的工作。当所有聚类中相对于其参考图的深度图都得到之后,把这些深度图综合到一起就是最终的密集重建结果了。下面就开始摘录一些有用的信息。
SURE 的 Image rectification 功能用到了两个算法:
文中提到图像矫正并不会改变图像光心的位置,只是改变了像面的朝向,可以想象成在同样的空间内用一块虚拟的像面截取了新的图像,所以原始图像中的像点和矫正图像的对应位置应该是可以用一个平面单应来表示的,另外就是空间点和图像光心的连线方向以及长度应该都是不发生改变的,这也是后面在做 check 的时候利用到的一点。
如下图所示,SURE 用到的 matching cost 有一下三种,一是 Census cost,一是 Mutual infomation,另外还有 DAISY 描述子(居然还有这个),其中 Census cost 是对参数最不敏感的。
SURE 的核心 tSGM 算法相对于原 SGM 算法最大的改进就于内存占用量的减少,和运算时间的缩短,tSGM 是怎么做的呢,它是基于金字塔 coarse to fine 的思想,通过高层金字塔提供的 disparity range 信息来 propagate 到低层金字塔并限制了底层金字塔的 disparity searching range,这样就极大的减少了对内存的需要,进而缩短了运算时间,并且文章声称这样还屏蔽了一些 outlier。
下面就详细描述描述 tSGM 是怎么做的,首先在金字塔的最高层,这时图像尺寸和分辨率比较小,为了达到文中声称的完全不需要视差的任何先验信息的特性,显然金字塔最高层的视差图的视差范围是整个图像的尺寸,这时存储 matching cost 和 aggregated cost 的结构是原来的那种长方体 cube 结构,也就是每个像素的可能视差范围是完全一样的。
最高层往后的层存储 cost 的结构就不再是这种简单的但很占内存的长方体结构了,见下图,假使第 l 层生成的经过了 left/right check 的视差图为 D(l),这个信息如何影响下一层,也就是 l-1 层每个像素的 disparity searching range 的呢?tSGM 是这样做的,对于 D(l) 中每个有效视差像素,取以其为中心的 7×7 的窗口内的最大视差值为 dmax,最小视差值为 dmin,并各自存入一个新的二维矩阵 Dmax(l) 和 Dmin(l),还要把该像素的视差值更新为该窗口内的中值,对于 D(l) 中每个无效视差像素,也就是被判为遮挡的那些像素同样是进行上述操作,只不过这时候的窗口变成一个 31×31 的窗口,要说明的是文中说 l 层中针对有效视差和无效视差像素的 disparity searching range 分别被限制为了 16 和 32 个像素,也就是说对于一个有效视差像素如果 dmax - dmin <= 16,那么 searching range 就是 dmin 到 dmax,否则的话会有一个截断以保证 range 为 16 个像素,我在想这个截断操作可就不是只有唯一的方式了,是从上截,还是从下截,亦或是以中值为中心上下各 8 像素,更或是以没更新为中值前的视差值为中心上下各 8 像素?这里还是个疑问,至少从这篇文章里还找不到明确的答案,各让人不解的是文中说拓展到 l-1 层时,D(l),Dmax(l) 和 Dmin(l) 被 upscaled 了,l-1 层中每个像素的视差搜索范围居然是 [2(xb+d-dmin) 2(xb+d+dmax)],我觉得应该是 [2(xb+dmin) 2(xb+dmax)],因为经过截断后得到的 dmin 和 dmax 已经定义了 l 层中视差范围的两个边界,到 l-1 层时只需要简单的拓展一下就行了啊,但是这样做的话中值化的 D(l) 貌似又没起到什么作用,反正关于这个问题 SURE 到底是怎么做的我是还没有搞的很明白,尽管从下图来看他们的意图很明显。
然后再截一张文中有关基于其提出的新的 cost 存储结构的 cost aggregation 策略:
好吧,我承认上面的式子我又没有完全理解,感觉有点矛盾,Lr 难道只跟 Cr 有关系吗?不是 像原 SGM 中那样是 Lr-1 吗?而且是当 d>dmax 和 d<dmin 时才加 P2,其它情况则是 Lr=Lr-1,WTF?还是按原 SGM 那样的策略来做不就行了吗?
再截一段文字描述了 tSGM 中的 left/right check,以及如何整合灰度边缘信息,还有如何排除大面积的无效非场景区域。
下面就来描述如何通过多个相对于参考图像的视差图基于 multi-view geometrical consistency check 来进行进一步的粗差剔除,深度融合以及最终非线性优化形式的 triangulation 的操作得到最终的相对于该聚类中参考图像的完整深度图。
每个相对于参考图的视差图其实都是经过了不同的图像矫正操作的,直接在这些不同视差图上去进行比较肯定是没意义的,因为这个视差图上的 i,j 像素实际并不同样对应其它视差图上的 i,j 像素,因此比较都是相对于没有任何矫正的原参考图像来做的。
原参考图上的每个像素 xb 依据各视差图 Dn 还有图像矫正参数 Tn 能计算得到一个物点光心连线长度,如下图所示,依据的就是上面描述的空间点和图像光心的连线方向以及长度不随图像矫正发生改变。
原参考图中的每个像素在每个视差图上都可以计算得到一个这样的长度,其实也就代表了沿像素光心射线方向上的不同物点位置,这些物点位置肯定有些是 outliers,即使不是 outliers 肯定所有的物点位置也不是完全重合的,SURE 是怎么剔除这些 outliers 和融合 inliers 的呢?它就是通过聚类,它认为每个视差的提取沿极线方向上是有一定不确定度的,该不确定度投射到像素射线方向上就是一个一维的区间,当多个物点的该区间有重合时,这多个物点就被聚为一类,认为是同一个物点,见下图示意。
这样的聚类准则下可能会出现多个聚类,这时就选择拥有物点数目最多的那个聚类当做最终的物点,当然 SURE 也强加了一个最小聚类数目的参数,也就是说当最大聚类的物点数目少于该参数时,该像素依然会被判为是个无效的像素,因为多图间的一致性不够高。而当最多数目的聚类有多个的时候,则选择平均交会角最小的那个聚类,如下所示。
上面说的 image space accuracies are correctly propagated 我的理解是指就是上述的视差不确定度是跟交会角度有关的,交会角大时对应的视差不确定度会大些。
然后就是交会,也就是说上述的聚类中会有多个物点,这些物点到底要融合到哪一个共同的物点位置呢?SURE 有两种交会策略可供选择,一个是在物方做的,也就是直接取这些物点的平均深度位置,如下式
另一种方法则是更合理的考虑到每个观测像点的方式,也就是迭代优化使得在所有 rectified match images 上的综合重投影残差最小化:
式子写是这么写,但是仔细想一想上面的式子实际上意味着什么呢?其实就是意味着该以一维深度诱导的在各视差图上的视差值应该与各视差图上原本通过 tSGM 得到的视差值差的平方和最小化,依据式子 (10) 上式其实可以写成如下形式
其中的 D 就是要迭代优化的一维深度变量,准确说是点心连线长度,而 (xr,yr) 坐标是原始未矫正的参考图像中的考察像素 xb 对应其在 m 个矫正参考图中的坐标,该坐标与 D 无关,该深度 D 诱导的在 (xr,yr) 处的视差值就是前面的除法部分,后面的 dm 则是通过 tSGM 得到的在 (xr,yr) 处的视差值,这个目标函数对 D 求导还是比较简单的,因为就分母那项跟 D 有关。很容易迭代优化得到最终的 D,而且 Design matrix ATA 是一个标量,都不用求矩阵逆,只需要求倒数就行了。
最后文中就是列了一堆实验结果,并进行了结果分析。
7. Non-parametric Local Transforms for Computing Visual Correspondence, (completely read on 7th May 2014).
Ramin Zabih from Cornell University 1994 年的一篇 ECCV 文章,介绍了两种 non-parametric local transforms,一个是 rank transform,一个是 census transform,这两个变换的定义非常的简单,总之都是基于邻域内像素灰度和中心像素灰度间的比较,只不过 rank transform 只是记录了满足要求的邻域像素的个数,而 census transform 则还按顺序完整记录了各比较结果,因此也就包含了局部的结构信息,这两种变化可以说都属于 binary feature。这两种变换提出的初衷就是对抗局部窗口内不满足统一统计特性的少数 outliers,尤其是遇到 depth discontinuity 时,如果使用通常的 SAD, SSD 或者 NCC 相似性度量时,会造成较大的误差,尤其是 NCC,因为这些度量是基于灰度信息,outliers 的灰度会产生较大的影响,如果是像这里提出的 transform 一样只基于相对灰度值大小比较的话,outliers 的影响就会减小很多,能获得更好的 depth discontinuity 精度,其实这种方式后来在 Hirschmuller 09 年的 PAMI 综述文章里还被拿来进行测试,在对抗 radiometric differences 方面也获得最高的评价。
8. The Complete Rank Transform: A Tool for Accurate and Morphologically Invariant Matching of Structures, (completely read on 8th May 2014).
Oliver Demetz 在 2013 年发表的一篇文章,作者不是很熟悉。文章中提出了所谓的 Complete Rank Transform (CRT),跟原 rank transform 和 census transform 相比的不同就在于其为邻域内每个像素就统计了灰度比较特性,并依然以 string 形式存储,就下面一张图就可以看出它的创新点在哪里,CRT 需要的存储空间无疑是会多很多,因为不能以 bit string 的方式存储了,严格上说不是一种 local binary pattern LBP。
9. A Census-Based Stereo Vision Algorithm Using Modified Semi-Global Matching and Plane Fitting to Improve Matching Quality, (completely read on 8th May 2014).
奥地利 M. Humenberger 2010 年的一篇 CVPR 文章,我觉得有点侧重于高效视觉系统算法的实现,核心思想就是采用了 census transform 作为 matching cost,然后在 SGM 框架下做全局优化,之后再对纹理不丰富也就是匹配不可靠(其实也就意味着纹理不丰富)进行平面拟合得到最终的 disparity map,为了减小原 SGM 方法对内存的使用率,他这里提出不在全图做 SGM,而是在一定像素宽的条带图像区域做 SGM,以较少内存占用,我觉得没什么太多意义,可能对 FPGA 实现确实有意义吧。
10. Performance Evaluation of a Census-Based Stereo Matching Algorithm on Embedded and Multi-Core Hardware, (completely read on 8th May 2014).
还是上文作者 M. Humenberger 2009 年的一篇文章,关于这篇文章没什么太多好提的,他里面都是把 09 年那时候出现的嵌入式的 real-time stereo matching systems 给列了一下。
然后值得一提的就是他里面提了一种评判视差置信度的标准:
11. Evaluation of Stereo Matching Costs on Images with Radiometric Differences, (completely read on 9th May 2014).
SGM 算法的作者德国大神 Heiko Hirschmuller 在 2009 年的一篇 PAMI 文章,好吧,这篇文章毫无争议的当选我心目中的二季度最佳文章,这里我的总结不再摘录其中的有用信息了,因为怕篇幅不够,其中的有价值的信息实在是太多了,扎扎实实看完这篇文章我感觉心情很愉悦,很充实。文章总共测试比较了 15 种 matching costs 结合 3 种 stereo methods 的效果,这 15 种 matching costs 被他分为 parametric, nonparametric 和 Mutual infomation 三大类,3 种 stereo methods 则分别是基于矩形窗的 WTA Local method,SGM 以及 Graph cut。测试集 Images without
Radiometric Changes, Simulated Radiometric Changes 和 Real Exposure and Light Source Changes 三大类。文章还测试了不同 costs 对不同测试集的稳定性,以及各 costs 的 Discriminability,还分析了采用 color 信息对匹配的意义,这里我就仅仅摘录下文章的结论吧。面对这样的好文章我只能是一直膜拜了。。。总结完毕。
12. Bilateral Filtering for Gray and Color Images, (completely read on 11th May 2014).
来自 Stanford University 和 S. Birchfield 一起提出 sampling insensible matching cost 的 Carlo Tomasi 在 1998 年的一篇 ICCV 文章。
文中提出了一种新的图像滤波方法 —— Bilateral Filtering,相比于传统的高斯滤波等只能利用 spatial offset 信息来进行滤波,也就是文中所谓的 domain filtering,BF 还结合了 photometric difference 信息,即文中所谓的 range filtering,BF 同时考虑了空域和灰度(或色彩)域的偏移量,所以作者称其为 bilateral filtering。也就是说在原来传统的例如高斯滤波中,参与滤波的邻域元素的权重随其与中心元素的 spatial distance 非线性下降的基础上,其权重还同时随其灰度或色彩与中心元素灰度或色彩之间的差非线性下降,就这么个意思。
Bilateral filtering 在能达到传统滤波效果的基础上同时还能非常好的保持图像边缘的锐度,这也正是其后来被应用于 stereo 前段滤波去除 stereo images 之间 photometric distortion 的原因。关于 BF 的详细表达式可以参考原文,其边缘保持的效果确实非常的好。另外文中介绍了一种 CIE-Lab 的色彩空间表达方式,据其称该色彩空间表示是最符合人眼认知的一种表达方式。
13. Enhanced Real-time Stereo Using Bilateral Filtering, (completely read on 11th May 2014).
该文来自 Jet Propulsion Laboratory, California Institution of Technology 的 Adnan Ansar,作于 2004 年。该文据上面文献 11 中所描述是第一次将 bilateral filtering 应用于 stereo vision。
stereo vision 中在做 SAD 之前通常需要通过某些手段去补偿 stereo images 之间的整体亮度差或色彩差,常用的方法是 background subtraction,也就是用原始图像减去通过高斯滤波以后的图像,通过高斯滤波的图像被认为主要是图像背景,左右两幅图像都做了这一操作之后它们之间的亮度或者色彩差就被补偿了。但是传统的高斯等滤波方法都会使得图像边缘出现泛化,因此该文利用 bilateral filtering 取代高斯滤波去做 background subtraction,进而在不损失边缘锐度的情况下去补偿左右图像间的灰度或色彩差,然后再去做 stereo,这就是该文最大的贡献,另外一个贡献就是文中提出二维 bilateral filtering 可以拆分成两次一维滤波去做,一次沿行方向,一次沿列方向,被称这样可以提高运行速度。
14. Adaptive Support-Weight Approach for Correspondence Search, (completely read on 13th May 2014).
这是韩国人 Kuk-Jin Yoon 2006 年在 PAMI 上发表的一篇文章,像很多其他学者一样,该文里的内容事先已经于 2005 年发表在了 CVPR 上面,现在感觉 CVPR 已经成了 PAMI 和 IJCV 的试金石,中了 CVPR 接下来就是中 PAMI 和 IJCV 了。
文章前言里提到匹配问题的歧义性随着相似性度量分辨力的提高而下降,而后文章将 local stereo methods 中跟 support window 相关的方法分成了 4 大类:
1. Adaptive-window methods,窗口个数还是只有一个,但会有选择机制来选择一个最优的支持窗口;
2. Multiple-window methods,预先设定好若干固定的窗口,然后每个窗口去计算一次相似度,最终选择相似度最高的作为最终的相似度;
3. Segmentation-based methods, 先通过灰度或颜色信息对图像进行分割,然后利用分割信息形成 support window;
4. Adaptive support-weight methods,单一窗口,窗口形状可以就是简单的矩形窗,但是其中每个像素的 support-weights 却是自适应各不相同的,该文方法就属于这一范畴。
其 adaptive support-weight 的思想和上面文献 [12] 中提出的 bilateral filtering 很相似,同样是同时利用了 spatial proximity 和 photometric similarity 信息,如果 spatial proximity 加权函数 wp(p,q) 是 p 和 q 欧式空间距离 △p(p,q) 的函数(一般可以是一个高斯核),而 photometric similarity 加权函数 ws(p,q) 是 p 和 q 色彩空间欧式距离(例如CIE-Lab空间)△s(p,q) 的函数(一般也是高斯核)的话,那么联合加权函数就是 w(p,q)=wp(p,q)*ws(p,q),按照 bilateral filtering 的用法的话就是 h(p) = ∑w(p,q)f(q)/∑w(p,q),其中 q∈N(p) 即在 p 的邻域内,f(q) 是 q 的灰度或者色彩。而按照 ASW 的用法,数学上就成了 cost(p,d) = ∑w(p,q)w(pd,qd)e(q,qd)/∑w(p,q)w(pd,qd),其中 pd, qd 分别是 p 和 q 在视差 d 的支持下在匹配视图中的对应像素,w(pd,qd) 是在联合加权情况下对 qd 点的加权值,e(q,qd) 则是参考图中 q 像素和匹配视图中对应 qd 像素之间的灰度差或者色彩差,可以是 AD、SD 或者该文中的 truncated AD,详细定义见原文。
对比 BF,可以发现 BF 仅仅是利用邻域对灰度进行滤波,所以就在原图上去做就行了,只涉及到一幅图;而 ASW 的目的则是要计算像素 p 在视差 d 时的 matching cost,牵扯到了两幅视图,因此出于对称性的考虑,参与 ASW matching cost 计算的在参考图和匹配图中的两个窗口内的元素都有各自的加权,即 w(p,q) 和 w(pd,qd),并且很显然 ASW 是对灰度差或色彩差即 AD、SD 或者 truncated AD 进行滤波,而不是像 BF 原文中那样仅仅对灰度或色彩进行滤波,说白了 ASW 本质上就是对 AD、SD or truncated AD 进行了 bilateral filtering,是对简单的 SAD、SSD or STAD matching costs 的一种改进。
该文中在计算得到 ASW matching cost 以后采用的是 WTA 的 local 机制来生成 disparity map,但是这种 matching cost 显然也可以加入 global optimization 机制。
15. Marching Cubes: A High Resolution 3D Surface Construction Algorithm, (completely read on 25th May 2014).
这是一篇 1987 年 ACM Siggraph Computer Graphics 的文章,作者是 William E. Lorensen 和 Harvey E. Cline,这篇文章现在的引用次数是 10486 次。。。我查了查 Lowe 的 SIFT IJCV 从 2004 年发表到现在的引用次数是 24000 多次,该文还是不及伟大的 Lowe 哈。
回归正题,别看该文名字里有 3D surface construction,其实它跟我们现在理解的三维表面重建还是不一样的,准确来说该文提出是一种从原始 3D original data or volume 中提取 三维等值面 isosurface 的方法,也就是说在一个三维数据中,把等于用户指定值的 surface 给提取出来,输出的是连通的 triangulated meshes。文章在其摘要中就声称该算法主要是面向三维医学数据,像核磁共振成像扫描得到的人体三维图像切片等,这种医学数据就是典型的三维离散数据,里面的单元是一个一个 voxel,也就是三维像素,每个 voxel 也有一个强度值,也就是 intensity,原文中说成是 density。我记得以前张老师叫我处理过一组这样的脑部切片图像,它里面不同的人体组织有不同的灰度值,骨骼一般灰度值比较高,软组织灰度值就比较低,显得较暗,但同一组织在不同切片图像上的灰度响应是一致的,比方说我们想从这样的三维数据中提取出整个人体骨骼的 surface,已知骨骼外边缘的灰度值恒为 255,那么我们就只需把每个切片图像中灰度值为 255 的像素取出来就行了,但是简单的这样做只能是得到彼此不相关联的一个个封闭的 curves,不在相邻切片图像间建立联系的话就这些独立的 curves 是无法重构出骨骼 surface 的,那么文章的方法就是每次同时考虑相邻的两层切片图像,上下对应各取 2×2=4 个像素,共 8 个像素组成一个 cube,这 8 个像素每个像素都和骨骼的灰度 255 去比较,也就是说每个像素会有 0 和 1 两种状态,真正的 bone surface 会切过该 cube 中那些一端灰度比 255 小,一端比 255 大的边,这个还是比较好理解的。
文中对 surface 和 cube 相交的形式总结归纳出了一下 15 种:
文中还提到要估计 triangle 每个 vertices 的法向值,我得说明一下的是,它这里的法向值其实是指的灰度法向值,而不是三维坐标法向值,其实想一想都已经得到 triangle 每个点的三维坐标了还有必要再显式的算一遍该 triangle 的表面法向吗?貌似没这个必要了。Anyway,文中算 vertex 灰度法向的方法是跟算其三维坐标的方法一样的,即先通过简单的中心差分得到 vertex 所在边两端像素的灰度梯度,然后再通过线性插值出该 vertex 的灰度梯度。等值面的法向其实可以用灰度梯度方向代替,这很好理解,等值面本身是灰度等值的面,灰度变化的主方向应该是和灰度等值面的法向方向一致的,这在二维图像上就能容易理解,二维图像上提取的等值曲线在某点的法向正是该点处灰度梯度的方向。
我还下了两篇有关等值面提取的文章 Octree-Based Decimation of Marching Cubes Surfaces 和 A Modified Look-Up Table for Implicit Disambiguation of Marching Cubes 都是对 Marching Cubes 方法进行了拓展或者改进,后面有空了可以再看一看。
16. A Volumetric Method for Building Complex Models from Range Images, (completely read on 26th May 2014).
该文是 M. Goesele 的 Multi-View Stereo Revisited 一文中使用的 depth fusion 方法的出处,作者是当时还就读于 Stanford University 的 Brian Curless 和 Marc Levoy,B. Curless 现在在 University of Washington 任教授。
总的来说该文的方法是一种对多个 depth maps 进行融合的方法,基本方式就是先利用所有 depth maps 的 depth 信息及其对应的不确定度来 render 一个 3D discrete volume,该 volume 表示了一个 cumulative weighted signed distance function,每一个单独的 depth map 可以用其对应的 signed distance function render 一次该 volume 中的每一个 voxel,所有的 signed distance function 按权重加权累加起来就得到该 cumulative weighted signed distance function,文章最终要提取的 surface 就是该 CWSDF volume 中的等于 0 的等值面,提取该等值面的方法正是文献【15】中的 Marching Cubes,还有 A Modified Look-Up Table for Implicit Disambiguation of Marching Cubes 一文的改进方法。要注意的是用 Marching cubes 方法提取的等值面就已经是 trianglated meshes surface 了。下面摘录一下文章的摘要,注意其称本文方法在最小二乘意义上是最优的。

文章的前言部分把 surface reconstruction from dense range data 方法分成两大类,一类是 reconstruction from unorganized points 一类则是 reconstruction that exploits the underlying structure of the acquired data。前者指的是对这些 unorganized points 之间的连通性没有任何的先验信息,而后者则是利用了数据本身的一些结构信息,比方说我的数据本身是一个 range image 的话,那么我每一个深度点属于一个像素,它和其 8-邻域 中的各像素间自然就存在连通性了,这就是可以加以利用的重要信息。这两大类方法按照其是构建 parametric surfaces 还是 implicit function 各自又可以分为两个子类,宇翔介绍的 Hoppe 1992 的方法属于 unorganized points/implicit function 方法,而本文的方法则是 structured data/implicit function 方法,因为其要处理的工作是融合多个 range images 并提取出一个统一的 surface。下面我开始详细复述一遍上述的 cumulative weighted signed distance function or volume 是如何建立的。
拿来第一张 range image or depth map 及其每个像素对应的权重值 weight map,如何渲染其对应的 signed distance volume 和 weight volume 呢?首先利用 depth map 每个像素和其 8-邻域 连通性可以自然的将 depth map 在空间中生成一个 triangulated mesh,不过当然要避免为 depth discontinuity 分配 edge,也就是要删除那些包含 edge length 长于一定阈值的 triangles;然后采用遍历两个 volume 中每个 voxel 的方式,每个 voxel 中心和光心连接成的射线将和上面形成的 mesh 交某个 triangle 于某一个点,voxel 中心与该交点的相对矢量就是该 voxel 对应的 signed distance value,然后该 voxel 对应的 weight 就是通过空间三角线性插值出来的。我在想实际中做的话应该不用再显式的生成一个 mesh,然后算空间交点什么的,而是直接把 voxel 重投影过来得到一个亚像素坐标,该亚像素坐标的深度值可以直接利用其所属 2D triangle 的三个像素的深度值给按二维三角线性插值出来,有了深度其实也就相当于有了三维坐标了,同样也就可以得到该 voxel 的 signed distance value,其 weight value 也可以通过二维三角线性插值出来,我这想的二维三角形去插值做应该是和三维三角形插值去做是完全一样的,但其实严格来说可能不一样,因为完全一样的前提条件得是 2D triangle 中的每个像点的深度随着像素边长线性变化,之前我推过,要是深度真是随像素边长线性变化的话,其对应的空间表面将不是一个平面,而是一个凹面,所以基于这样的前提,2D triangle 在空间中将不对应一个 3D triangle,那么插值出来的深度和 weight 将会有出入,但这个出入我认为还是会很小的,毕竟一个 2D triangle 的边长也就是一整像素,这样的近似带来的误差到底有多大还得仿真看看。
上面遍历每个 voxel 之后就有了第一个 signed distance volume Di(x) 和 weight volume Wi(x),它和新来的 depth map 的 di+1(x) 及 wi+1(x) 按下式来融合得到新的 Di+1(x) 和 Wi+1(x):

第 i 个 cumulative weighted signed distance function or volume Di(x) 中的 surface 就通过 marching cubes 算法提取出 0 等值面得到。
文章后面还讲了如何做 hole filling 和 smoothing,还有预先通过 resampling depth map 让其行方向和 volume scanline 方向对齐以做快速同步扫描等,总结部分还列出了一些方法的局限性等,我只是稍作了解。看懂本文方法之后我觉得还真有可能把它给用上。
17. Surface Reconstruction from Unorganized Points, (completely read on 27th May 2014).
这就是宇翔向我推荐的 surface reconstruction 的文章,作者是 University of Washington 的 Hugues Hoppe。该文章方法面向的问题是从几乎没有任何先验信息的一堆 unorganized points 中去重建 surface,如此一来该方法从表面上看貌似适用于所有测量手段得到的点云,但也因此说明该方法应该不是针对哪种测量数据是最优的,实际上该方法也不是完全不需要先验信息的,他的算法需要知道点云的整体密度以及精度。
好,开始复述方法流程:
1、首先为所有的测量空间点找到其 knn 最邻近点,然后算其和这 k 个邻近构成的点集的 centroid O,并利用主成分分析方法算得该点集张开空间的最小特征向量,也就是对应了该点集空间的法向 n,当然由于所有数据点没有任何方位信息,因此该法向的方向还是未定的,我在想我做的空间 patch 的法向也可以这样来求得,当然要借助其与观测图像的相对关系来消除法向歧义性。文中声称该平面 (O, n) 是对真实 surface 在 O 处切平面的线性估计,还称直接用这些估计的切平面去作为最终的 surface 效果并不好,呈现出非常复杂的非流型结构 non-manifold structure,因此文中的做法是利用这些估计的切平面去构造 signed distance volume,并用 marching cubes 方法去提取其中的 zero set 等值面作为最终的 surface。
2、上面说的为每个测量点 x 都算了一个平面 (O, n),但其实其法向的方向是未定的,需要为每个切平面赋上一致的法向,否则 signed distance volume 就会是乱的,文中采用的做法是由某个法向按照邻域连接性 propagate 到其它的切平面去,首先要做的就是确定连通性,即哪些切平面之间是相连的,文中采用的是 Euclidean Minimum Spanning Tree (EMST) 结合 knn 邻域的方法建立了一种所谓的 Riemannian Graph 来表示各切平面的连通性。
3、然后开始从某个切平面传递法向到邻域切平面,文中声称法向传递的顺序有很重要的影响,他的做法是当前的切平面法向只传递给邻域中与之最平行的切平面,即 1-|ni*nj| 最小的切平面,也就是 traversing the minimal spanning tree (MST) of the graph in depth-first order。
4、接着就生成包裹了所有切平面的离散 volume 空间,对于其中的每个 voxel 都找到与其最邻近的切平面 (O, n),并在其上做投影点,如果该投影点离所有原始测量点集的距离太大,超过了先验已知的整体点密度和精度之和,说明该 voxel 应该是在 surface boundary 之外了,那么该 voxel 就被定为 undefined,后续找等值面不予考虑了,要是没超过,那么其与其投影点之间的矢量距离就被当作 signed distance value 赋给了该 voxel,遍历完该 volume 之后,signed distance volume 就生成了。
5、接下来就是利用 marching cubes 方法来做 zero set 等值面提取了,输出的就是 triangulated mesh。
和宇翔讨论的时候我们都在想一个问题,在估计完切平面之后为什么不拿原始测量点在对应的切平面上去进行投影,然后在所有投影点上去做三角化得到 mesh 作为最终的 surface?现在想想可以这么理解吧,如果这样去做的话那么跟直接拿估计的切平面当作 surface 就没区别了,而文中说过直接拿切平面做 surface 得到的是一个 non-manifold structure,效果很差,因此建立离散 signed distance volume 去找等值面,可能 marching cubes 方法可以保证形成 manifold 吧,隐性的代入了更多的平滑作用。
另外关于文献【16】方法和本文方法的不同,假设原始数据就只有一张 depth map,那么利用【16】的方法得到的结果将是就是基于该原始 depth map 生成的 triangulated mesh,因为没有多余观测,就一张 depth map,没有其它的,当然由于 marching cubes 本身对空间进行了离散,其实 marching cubes 也有些许平滑的效果,但 marching cubes 输入数据本身就是该 depth map 没有利用邻域深度数据对其进行平滑,而本文方法即使是单张 depth map,也会利用 knn 邻域点估计切平面,也就是进行了平滑,【16】中的方法主要依靠的是重复观测,没有强加邻域平滑项,且每单个测量点有自己的不确定度,从测量理论的角度来说【16】中的方法显然更符合测量原理,精度也会更高。
我还下了两篇有关等值面提取的文章 Octree-Based Decimation of Marching Cubes Surfaces 和 A Modified Look-Up Table for Implicit Disambiguation of Marching Cubes 都是对 Marching Cubes 方法进行了拓展或者改进,后面有空了可以再看一看。
16. A Volumetric Method for Building Complex Models from Range Images, (completely read on 26th May 2014).
该文是 M. Goesele 的 Multi-View Stereo Revisited 一文中使用的 depth fusion 方法的出处,作者是当时还就读于 Stanford University 的 Brian Curless 和 Marc Levoy,B. Curless 现在在 University of Washington 任教授。
总的来说该文的方法是一种对多个 depth maps 进行融合的方法,基本方式就是先利用所有 depth maps 的 depth 信息及其对应的不确定度来 render 一个 3D discrete volume,该 volume 表示了一个 cumulative weighted signed distance function,每一个单独的 depth map 可以用其对应的 signed distance function render 一次该 volume 中的每一个 voxel,所有的 signed distance function 按权重加权累加起来就得到该 cumulative weighted signed distance function,文章最终要提取的 surface 就是该 CWSDF volume 中的等于 0 的等值面,提取该等值面的方法正是文献【15】中的 Marching Cubes,还有 A Modified Look-Up Table for Implicit Disambiguation of Marching Cubes 一文的改进方法。要注意的是用 Marching cubes 方法提取的等值面就已经是 trianglated meshes surface 了。下面摘录一下文章的摘要,注意其称本文方法在最小二乘意义上是最优的。
文章的前言部分把 surface reconstruction from dense range data 方法分成两大类,一类是 reconstruction from unorganized points 一类则是 reconstruction that exploits the underlying structure of the acquired data。前者指的是对这些 unorganized points 之间的连通性没有任何的先验信息,而后者则是利用了数据本身的一些结构信息,比方说我的数据本身是一个 range image 的话,那么我每一个深度点属于一个像素,它和其 8-邻域 中的各像素间自然就存在连通性了,这就是可以加以利用的重要信息。这两大类方法按照其是构建 parametric surfaces 还是 implicit function 各自又可以分为两个子类,宇翔介绍的 Hoppe 1992 的方法属于 unorganized points/implicit function 方法,而本文的方法则是 structured data/implicit function 方法,因为其要处理的工作是融合多个 range images 并提取出一个统一的 surface。下面我开始详细复述一遍上述的 cumulative weighted signed distance function or volume 是如何建立的。
拿来第一张 range image or depth map 及其每个像素对应的权重值 weight map,如何渲染其对应的 signed distance volume 和 weight volume 呢?首先利用 depth map 每个像素和其 8-邻域 连通性可以自然的将 depth map 在空间中生成一个 triangulated mesh,不过当然要避免为 depth discontinuity 分配 edge,也就是要删除那些包含 edge length 长于一定阈值的 triangles;然后采用遍历两个 volume 中每个 voxel 的方式,每个 voxel 中心和光心连接成的射线将和上面形成的 mesh 交某个 triangle 于某一个点,voxel 中心与该交点的相对矢量就是该 voxel 对应的 signed distance value,然后该 voxel 对应的 weight 就是通过空间三角线性插值出来的。我在想实际中做的话应该不用再显式的生成一个 mesh,然后算空间交点什么的,而是直接把 voxel 重投影过来得到一个亚像素坐标,该亚像素坐标的深度值可以直接利用其所属 2D triangle 的三个像素的深度值给按二维三角线性插值出来,有了深度其实也就相当于有了三维坐标了,同样也就可以得到该 voxel 的 signed distance value,其 weight value 也可以通过二维三角线性插值出来,我这想的二维三角形去插值做应该是和三维三角形插值去做是完全一样的,但其实严格来说可能不一样,因为完全一样的前提条件得是 2D triangle 中的每个像点的深度随着像素边长线性变化,之前我推过,要是深度真是随像素边长线性变化的话,其对应的空间表面将不是一个平面,而是一个凹面,所以基于这样的前提,2D triangle 在空间中将不对应一个 3D triangle,那么插值出来的深度和 weight 将会有出入,但这个出入我认为还是会很小的,毕竟一个 2D triangle 的边长也就是一整像素,这样的近似带来的误差到底有多大还得仿真看看。
上面遍历每个 voxel 之后就有了第一个 signed distance volume Di(x) 和 weight volume Wi(x),它和新来的 depth map 的 di+1(x) 及 wi+1(x) 按下式来融合得到新的 Di+1(x) 和 Wi+1(x):
第 i 个 cumulative weighted signed distance function or volume Di(x) 中的 surface 就通过 marching cubes 算法提取出 0 等值面得到。
文章后面还讲了如何做 hole filling 和 smoothing,还有预先通过 resampling depth map 让其行方向和 volume scanline 方向对齐以做快速同步扫描等,总结部分还列出了一些方法的局限性等,我只是稍作了解。看懂本文方法之后我觉得还真有可能把它给用上。
17. Surface Reconstruction from Unorganized Points, (completely read on 27th May 2014).
这就是宇翔向我推荐的 surface reconstruction 的文章,作者是 University of Washington 的 Hugues Hoppe。该文章方法面向的问题是从几乎没有任何先验信息的一堆 unorganized points 中去重建 surface,如此一来该方法从表面上看貌似适用于所有测量手段得到的点云,但也因此说明该方法应该不是针对哪种测量数据是最优的,实际上该方法也不是完全不需要先验信息的,他的算法需要知道点云的整体密度以及精度。
好,开始复述方法流程:
1、首先为所有的测量空间点找到其 knn 最邻近点,然后算其和这 k 个邻近构成的点集的 centroid O,并利用主成分分析方法算得该点集张开空间的最小特征向量,也就是对应了该点集空间的法向 n,当然由于所有数据点没有任何方位信息,因此该法向的方向还是未定的,我在想我做的空间 patch 的法向也可以这样来求得,当然要借助其与观测图像的相对关系来消除法向歧义性。文中声称该平面 (O, n) 是对真实 surface 在 O 处切平面的线性估计,还称直接用这些估计的切平面去作为最终的 surface 效果并不好,呈现出非常复杂的非流型结构 non-manifold structure,因此文中的做法是利用这些估计的切平面去构造 signed distance volume,并用 marching cubes 方法去提取其中的 zero set 等值面作为最终的 surface。
2、上面说的为每个测量点 x 都算了一个平面 (O, n),但其实其法向的方向是未定的,需要为每个切平面赋上一致的法向,否则 signed distance volume 就会是乱的,文中采用的做法是由某个法向按照邻域连接性 propagate 到其它的切平面去,首先要做的就是确定连通性,即哪些切平面之间是相连的,文中采用的是 Euclidean Minimum Spanning Tree (EMST) 结合 knn 邻域的方法建立了一种所谓的 Riemannian Graph 来表示各切平面的连通性。
3、然后开始从某个切平面传递法向到邻域切平面,文中声称法向传递的顺序有很重要的影响,他的做法是当前的切平面法向只传递给邻域中与之最平行的切平面,即 1-|ni*nj| 最小的切平面,也就是 traversing the minimal spanning tree (MST) of the graph in depth-first order。
4、接着就生成包裹了所有切平面的离散 volume 空间,对于其中的每个 voxel 都找到与其最邻近的切平面 (O, n),并在其上做投影点,如果该投影点离所有原始测量点集的距离太大,超过了先验已知的整体点密度和精度之和,说明该 voxel 应该是在 surface boundary 之外了,那么该 voxel 就被定为 undefined,后续找等值面不予考虑了,要是没超过,那么其与其投影点之间的矢量距离就被当作 signed distance value 赋给了该 voxel,遍历完该 volume 之后,signed distance volume 就生成了。
5、接下来就是利用 marching cubes 方法来做 zero set 等值面提取了,输出的就是 triangulated mesh。
和宇翔讨论的时候我们都在想一个问题,在估计完切平面之后为什么不拿原始测量点在对应的切平面上去进行投影,然后在所有投影点上去做三角化得到 mesh 作为最终的 surface?现在想想可以这么理解吧,如果这样去做的话那么跟直接拿估计的切平面当作 surface 就没区别了,而文中说过直接拿切平面做 surface 得到的是一个 non-manifold structure,效果很差,因此建立离散 signed distance volume 去找等值面,可能 marching cubes 方法可以保证形成 manifold 吧,隐性的代入了更多的平滑作用。
另外关于文献【16】方法和本文方法的不同,假设原始数据就只有一张 depth map,那么利用【16】的方法得到的结果将是就是基于该原始 depth map 生成的 triangulated mesh,因为没有多余观测,就一张 depth map,没有其它的,当然由于 marching cubes 本身对空间进行了离散,其实 marching cubes 也有些许平滑的效果,但 marching cubes 输入数据本身就是该 depth map 没有利用邻域深度数据对其进行平滑,而本文方法即使是单张 depth map,也会利用 knn 邻域点估计切平面,也就是进行了平滑,【16】中的方法主要依靠的是重复观测,没有强加邻域平滑项,且每单个测量点有自己的不确定度,从测量理论的角度来说【16】中的方法显然更符合测量原理,精度也会更高。
订阅:
评论 (Atom)